هوش مصنوعی (AI) به توانایی ماشینها برای تقلید از هوش انسان و اقدامات برای انجام کارهای رسمی، تکراری و پیچیده با حداقل دخالت انسان اشاره دارد. یادگیری ماشینی و یادگیری عمیق زیر مجموعه های هوش مصنوعی هستند. اگر در علم داده یا نقشی مشابه کار می کنید، می توانید از یادگیری تفاوت بین این دو اصطلاح بهره مند شوید. در این مقاله، ما به یادگیری عمیق در مقابل یادگیری ماشین نگاه می کنیم، تعاریف آنها را برجسته می کنیم، مراحل استفاده موثر از آنها را به اشتراک می گذاریم، انواع هر یک را بررسی می کنیم و تفاوت های دیگر بین این دو مفهوم را بررسی می کنیم.
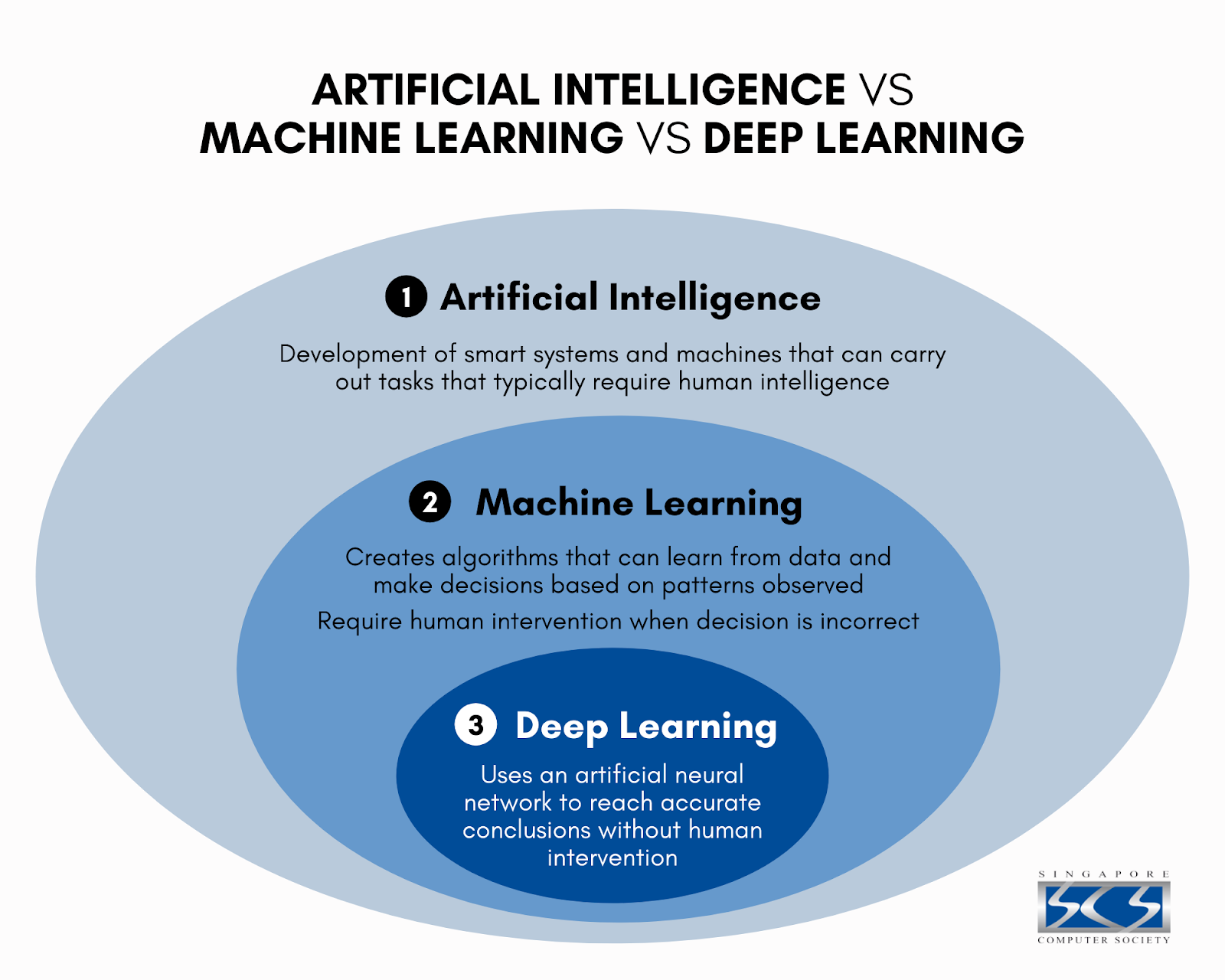
تعریف یادگیری عمیق در مقابل یادگیری ماشینی
درک یادگیری عمیق در مقابل یادگیری ماشین می تواند به شما کمک کند هنگام کار با موارد مختلف استفاده از هوش مصنوعی تصمیم بگیرید که از کدام یک استفاده کنید. یادگیری ماشین (ML) ماشین را قادر می سازد تا مجموعه ای از وظایف را بدون نیاز به برنامه نویس برای نوشتن دستورالعمل های خاص انجام دهد. یک الگوریتم یادگیری ماشینی مقادیر زیادی از داده ها را برای شناسایی الگوها و روندها تجزیه و تحلیل می کند و به آن امکان می دهد پیش بینی ها و پیش بینی های دقیقی انجام دهد. یادگیری عمیق (DL) زیرمجموعه ای از یادگیری ماشینی است که به ماشین اجازه می دهد بدون نظارت یاد بگیرد و پیشرفت کند. یک مدل یادگیری عمیق با هر تکرار پیچیده تر و دقیق تر می شود.
یادگیری ماشینی چیست؟
ML زیرمجموعهای از هوش مصنوعی است که سیستمها را قادر میسازد از دادههای ورودی یاد بگیرند، الگوهای پنهان را شناسایی کنند و با کمترین مداخله انسانی تصمیم بگیرند. یک مدل ML از مجموعه داده آموزشی یاد می گیرد تا روی مجموعه داده آزمایشی که شامل داده های دیده نشده است، پیش بینی کند. ML کاربردهای مختلفی دارد، مانند تشخیص تقلب، توصیه محصول، تشخیص تصویر و معامله در بازار سهام. به عنوان مثال:
مجموعه داده مسکن حاوی اطلاعات خانه های مختلف، قیمت آنها و نام متغیرهایی است که قیمت ها به آنها بستگی دارد. متغیرها شامل درآمد، جمعیت شهر، سن، میزان جرم و جنایت در منطقه، میانگین تعداد اتاق در هر خانه، میانگین تعداد اتاق خواب در هر خانوار و طول و عرض جغرافیایی است. وظیفه پیش بینی قیمت یک خانه در شهر با استفاده از متغیرهای موجود است. این نمونه ای از یک کار یادگیری ماشینی است که در آن می توانید مدل را برای تشخیص ویژگی ها یا متغیرهای مفید در پیش بینی قیمت خانه آموزش دهید.
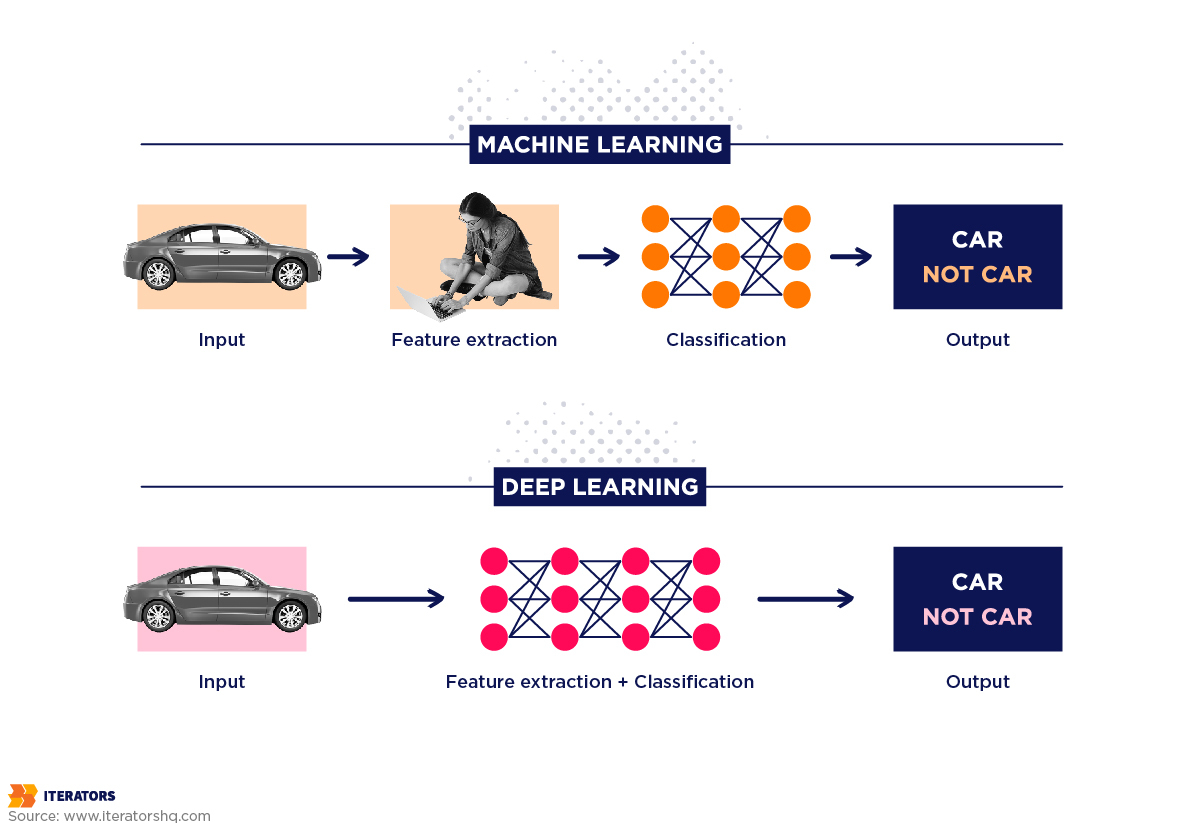
مراحل استفاده موثر از ML
ساخت یک مدل ML شامل مراحل زیر است:
-
داده ها را جمع آوری کنید. بسته به مورد استفاده، می توانید داده ها را از مجموعه داده های آنلاین، پایگاه های داده و مکان های ذخیره سازی خاص شرکت جمع آوری کنید. اطمینان حاصل کنید که داده ها به اندازه کافی بزرگ هستند تا یک مدل ML بسازید.
-
داده ها را از قبل پردازش کنید. داده ها را تمیز و سازماندهی کنید تا برای ورود به مدل آماده شوند. این شامل حذف مقادیر از دست رفته و نقاط پرت، هموارسازی و تبدیل داده ها و کاهش داده می شود.
-
تجزیه و تحلیل داده های اکتشافی را انجام دهید. این یک مرحله مقدماتی برای کشف الگوها، حذف ناهنجاری ها، درک همبستگی بین متغیرها و دریافت یک ایده کلی از مشکل است. در این مرحله می توانید از روش های بصری مانند هیستوگرام، نمودار زوجی، نمودار پراکندگی و سایر کتابخانه ها استفاده کنید.
-
یک مدل انتخاب کنید. هنگام تصمیم گیری در مورد استفاده از مدل ML، عواملی مانند عملکرد، پیچیدگی، اندازه داده، ابعاد، زمان و هزینه آموزش را در نظر بگیرید. میتوانید قبل از در نظر گرفتن مدلهای پیچیده، مانند مدلهای جنگل تصادفی یا درختهای تصمیم، با مدلهای ساده، مانند رگرسیون خطی یا چندجملهای شروع کنید.
-
مدل را ارزیابی کنید. در مرحله آخر، از معیارهای عملکرد برای ارزیابی عملکرد مدل استفاده کنید. معیارهای مختلفی برای مدل های رگرسیون و طبقه بندی وجود دارد.
یادگیری عمیق چیست؟
DL زیرمجموعه ای از ML است که ماشین ها را قادر می سازد با مثال یاد بگیرند. الگوریتمهای یادگیری عمیق سیستمها را قادر میسازند تا الگوهای پیچیده در دادهها را به تنهایی با استفاده از لایههای پردازشی متعدد تشخیص دهند. DL دارای چندین برنامه کاربردی مانند ماشین های خودران، ترجمه زبان، تشخیص بیماری ها با استفاده از تجزیه و تحلیل تصویر، تشخیص اشیا و ربات های گفتگو است. به عنوان مثال:
یک مجموعه داده شامل 500000 تصویر است که هر تصویر می تواند به یکی از 1500 گروه یا کلاس تعلق داشته باشد. وظیفه این است که طبقات اشیاء را در یک تصویر پیشبینی کنید و کادرهای مرزی را در اطراف آنها ترسیم کنید. به عنوان مثال، اگر یک تصویر شامل یک سگ و یک کودک نوپا باشد، سیستم نیاز به شناسایی هر دو شی به عنوان کلاس های مجزا و ترسیم جعبه های مرزی در اطراف هر شی دارد. مجموعه آموزشی شامل حاشیه نویسی است که اطلاعات بیشتری را در مورد آنچه تصویر نشان می دهد در اختیار مدل قرار می دهد. این نمونه ای از یک کار یادگیری عمیق است که شما را ملزم به آموزش یک شبکه عصبی کانولوشن می کند.
مراحل استفاده موثر از DL
ساخت مدل های DL شامل مراحل زیر است:
-
داده ها را جمع آوری کنید. بسته به مورد استفاده، میتوانید دادهها را از پایگاههای داده تصویر، دادههای خراششده وب یا ذخیرهسازی دادههای یک شرکت جمعآوری کنید. برای آموزش مدل های DL به حجم عظیمی از داده ها نیاز دارید.
-
پیش پردازش داده ها این مرحله شامل تغییر اندازه داده های خام به قالبی است که یک مدل بتواند آن را بپذیرد. همچنین میتوانید دادهها را برای حذف جزئیات غیر ضروری، بهبود ویژگیهای مهم یا کاهش اعوجاجهایی که ممکن است باعث سوگیری شوند، از قبل پردازش کنید.
-
معماری را تعریف کنید. از شبکههای عصبی کانولوشنال برای کارهای مربوط به تقسیمبندی تصویر، طبقهبندی و تشخیص و شبکههای عصبی تکراری یا مدلهای ترانسفورماتور از پیش آموزشدیده برای دادههای متنی استفاده کنید. همچنین میتوانید آموزش انتقالی را انتخاب کنید، که از یک مدل از پیش آموزشدیده با آموزش اضافی در مجموعه داده جدید استفاده میکند.
-
مدل را کامپایل کنید. این مرحله شامل پیکربندی شبکه عصبی برای فرآیند آموزش است. برای بهبود دقت مدل می توانید پارامترهایی مانند اندازه دسته و بهینه ساز را مشخص کنید.
-
مدل را برازش کنید. پس از تعریف معماری و تدوین مدل، مدل را برای تعداد ثابتی از دوره ها آموزش دهید. هنگامی که خطا، یعنی تفاوت بین خروجی مورد نظر و مورد انتظار، حداقل باشد، می توانید آموزش شبکه را متوقف کنید.
-
مدل را ارزیابی کنید. می توانید مدل آموزش دیده را روی مجموعه داده آزمایشی اجرا کنید تا دقت یک مدل را تأیید کنید.
انواع یادگیری ماشینی
در زیر دسته بندی های مختلف یادگیری ماشین وجود دارد:
یادگیری تحت نظارت
یادگیری نظارت شده نوعی از یادگیری ماشینی است که در آن میتوانید مدلها را با استفاده از دادههای آموزشی با برچسبگذاری مناسب برای طبقهبندی یا پیشبینی دقیق نتایج آموزش دهید. به عنوان مثال، یک مجموعه داده می تواند حاوی تصاویر و برچسب های آنها باشد که به طور منحصر به فرد اشیاء مختلف موجود در تصویر را شناسایی می کند. الگوریتمهای رایج مورد استفاده شامل درختهای تصمیم، جنگل تصادفی، ماشینهای بردار پشتیبان (SVM) و رگرسیون لجستیک هستند.
یادگیری بدون نظارت
یادگیری بدون نظارت شامل هیچ مجموعه داده برچسبگذاریشدهای نیست، که به مدل نیاز دارد تا الگوهایی را در مجموعه دادههای آموزشی بدون ساختار، سازمانیافته و بدون برچسب بیاموزد. این قابل مقایسه با مغز انسان است که اطلاعات جدید را می آموزد. می توانید از آنها برای مشکلات خوشه بندی، تداعی و کاهش ابعاد استفاده کنید.
یادگیری تقویتی
یادگیری تقویتی از یک سیستم مبتنی بر پاداش برای پاداش دادن به رفتارهای مورد نظر و تنبیه رفتارهای نادرست یا نامطلوب استفاده می کند. این امر مستلزم یادگیری رفتار بهینه در یک محیط خاص برای به حداکثر رساندن خروجی است. این کاربردهای زیادی دارد، مانند اتومبیل های خودران، کنترل چراغ راهنمایی و تشخیص پزشکی خودکار.
انواع الگوریتم های یادگیری عمیق
در زیر دسته بندی های مختلف یادگیری ماشین وجود دارد:
شبکه های عصبی کانولوشنال
شبکههای عصبی کانولوشنال (CNN) دستهای از شبکههای عصبی برای طبقهبندی و تشخیص تصاویر هستند. آنها حاوی لایههای کاملاً متصل، لایههای max-pooling و لایههای کانولوشن هستند. دسته ای از تصاویر را به عنوان ورودی می گیرد، ویژگی های آنها را استخراج می کند و طبقه بندی را انجام می دهد. برای هر کلاس یک پیش بینی احتمال مانند خروجی می دهد.
شبکه های عصبی مکرر
شبکههای عصبی مکرر (RNN) دستهای از شبکههای عصبی برای ترجمه ماشینی، تشخیص گفتار، خلاصهسازی متن و سایر موارد استفاده مرتبط با دادههای سری زمانی یا ترتیبی هستند. آنها از حلقه های بازخورد برای پردازش داده ها استفاده می کنند که با سایر شبکه های عصبی که ممکن است از چندین لایه پنهان در معماری خود استفاده کنند، متفاوت است. استفاده از یک حلقه بازخورد اجازه می دهد تا اطلاعات باقی بماند.
تفاوت های دیگر بین یادگیری عمیق و یادگیری ماشینی
در اینجا چند تفاوت بیشتر بین این دو عبارت وجود دارد:
منابع
یادگیری عمیق به سخت افزار بسیار قدرتمندتری برای پردازش مقادیر زیادی داده و انجام محاسبات پیچیده ریاضی نسبت به الگوریتم های ساده یادگیری ماشین نیاز دارد. واحدهای پردازش گرافیکی (GPU) برای سخت افزار یادگیری عمیق ضروری هستند. GPU ها می توانند چندین محاسبات را به طور همزمان انجام دهند و به صورت موازی مقیاس شوند تا مجموعه داده های بزرگ را در خود جای دهند. ماشینهای ارزانقیمت میتوانند برنامههای یادگیری ماشینی را به طور موثر و بدون مصرف انرژی پردازشی زیاد اجرا کنند.
زمان تمرین
آموزش مدل های DL به دلیل تعداد زیادی پارامتر و محاسبات پیچیده ریاضی به زمان زیادی نیاز دارد. این بسیار بیشتر از زمان مورد نیاز برای آموزش مدل های ML است. مدلهایی که با ML آموزش داده میشوند چند ثانیه تا چند ساعت طول میکشند، در حالی که مدلهایی که با DL آموزش دیدهاند ممکن است چند هفته طول بکشد. چندین مشکل با استفاده از آمار و تجسم یا یادگیری ماشینی قابل حل هستند. قبل از در نظر گرفتن یادگیری عمیق، مهم است که راه حل های ساده تری را امتحان کنید.
نوع داده و کاربرد
شما می توانید یک الگوریتم ML را بر اساس کار، مانند رگرسیون، طبقه بندی یا خوشه بندی انتخاب کنید. اگر با موارد استفاده ای مواجه می شوید که راه حل های مبتنی بر قانون ندارند، نیاز به تجزیه و تحلیل داده های تاریخی برای پیش بینی ها یا شامل شناسایی الگوها از مجموعه داده های بزرگ است، می توانید تصمیم بگیرید که یک مدل ML بسازید. امکان استفاده از DL برای مشکلاتی که حجم زیادی از داده های بدون ساختار دارند، مانند تصاویر، متن، صدا و ویدئو وجود دارد. یک الگوریتم DL را بر اساس کار انتخاب کنید، مانند طبقه بندی تصویر، پیش بینی رگرسیون یا پردازش زبان طبیعی.