داستانی کوچک در مورد تکامل یادگیری عمیق از مطالعه مغز انسان تا ساختن الگوریتم های پیچیده
در این وبلاگ، جنبه های نظری یادگیری عمیق (DL) و چگونگی تکامل آن، درست از مطالعه مغز انسان تا ساخت الگوریتم های پیچیده را خواهید آموخت. در مرحله بعد، شما به چند بخش تحقیقاتی نگاه خواهید کرد که توسط افراد مشهور یادگیری عمیق انجام شده است که پس از آن نهال را در مزارع DL کاشته اند که اکنون به یک درخت غول پیکر تبدیل شده است. در نهایت، شما با برنامه ها و زمینه هایی که یادگیری عمیق در آنها جای پای محکمی ایجاد کرده است، آشنا خواهید شد.
یادگیری عمیق: تاریخچه مختصر
در دهه گذشته، هیچ فناوری دیگری جز هوش مصنوعی مهم نبود. اندرو NG از دانشگاه استنفورد آن را «الکتریسیته جدید» نامید و چندین غول فناوری، از جمله گوگل، مایکروسافت و اپل، استراتژیهای تجاری خود را تغییر دادهاند تا به شرکتهای «اول هوش مصنوعی» تبدیل شوند. و ما می توانیم از Deep Learning برای همه اینها تشکر کنیم. قبل از شروع، بیایید بفهمیم DL در مورد چیست و دلیل تبلیغات آن چیست.
یادگیری عمیق، زیر مجموعه ای از هوش مصنوعی، یک تکنیک کامپیوتری برای استخراج و تبدیل داده ها با استفاده از چندین لایه مصنوعی از شبکه های عصبی است. این لایه ها حاوی مجموعه ای از نورون های مصنوعی هستند که در حالت خاصی وجود دارند. وقتی داده ها به این لایه ها ارسال می شوند، هر لایه ورودی لایه های قبلی را می گیرد و به تدریج آنها را اصلاح می کند. سپس لایه ها توسط الگوریتم هایی آموزش داده می شوند که به طور مداوم خطاها را کاهش می دهند و دقت پیش بینی آنها را بهبود می بخشند. به این ترتیب، شبکه یاد می گیرد که یک کار خاص را انجام دهد.

DL در مقایسه با الگوریتمهای سنتی هوش مصنوعی و یادگیری ماشینی (ML) کند است و در عین حال سادهتر و قدرتمندتر است. از این رو، اینها در حوزه های مختلف اعم از پزشکی، علم، اجتماعی، تولید، زنجیره تامین، رباتیک و بسیاری موارد دیگر بر اساس یک مدل ابتکاری واحد: شبکه عصبی استفاده می شوند. اگر نمیدانید که تاریخ DL به چه زمانی برمیگردد، اجازه دهید روشن کنم که بالاخره جدید نیست. از دهه 1940 وجود داشته است. بیایید به تاریخ بگردیم تا ببینیم اینها گهگاهی چگونه تکامل یافته اند.
مدل مککالوخ پیتس (MCP)
شبکه های عصبی اولین بار در سال 1944 توسط وارن مک کالو و والتر پیتس، دو محقق دانشگاه شیکاگو که در سال 1952 به عنوان اعضای موسس اولین بخش علوم شناختی به MIT نقل مکان کردند، پیشنهاد شد . هدف از تحقیق آنها با عنوان ” حساب منطقی ایده های ماندگار در فعالیت عصبی ” این بود که بفهمند چگونه مغز می تواند الگوهای بسیار پیچیده ای را با استفاده از سلول های به هم پیوسته تولید کند. همین تئوری به آنها کمک کرد تا یک شبکه عصبی ساده را با استفاده از مدارهای الکترونیکی که از یک نورون واقعی الهام گرفته شده بود، مدل کنند. به عقیده محققان، این مقاله سرآغاز شبکه های عصبی مصنوعی تلقی می شود، اگرچه نظرات و سوالات متفاوتی وجود دارد.
ساختار نورونها به نام نورون MCP (مککالوخ پیتس) نامگذاری شد. نورون MCP معمولاً دروازه آستانه خطی نامیده می شود زیرا ورودی ها را در دو کلاس مختلف طبقه بندی می کند. از نظر ریاضی، تابع گام خطی به صورت زیر تعریف می شود:
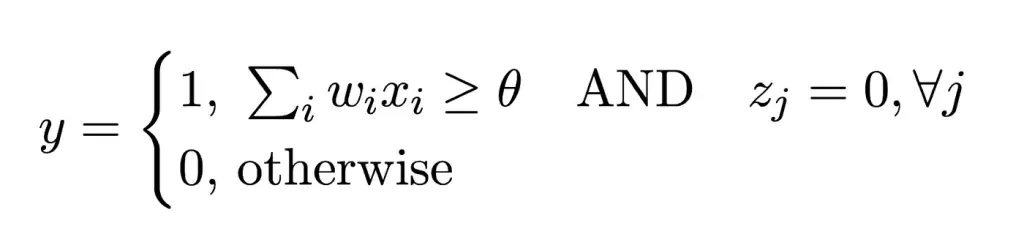
- y مخفف خروجی است
- xi مخفف سیگنال های ورودی است
- wi مخفف وزن های مربوط به یک نورون است
- Zj مخفف ورودی بازدارنده است
- Θ مخفف آستانه است
عملکرد به گونه ای طراحی شده است که فعالیت هر ورودی بازدارنده به طور کامل از تحریک نورون در هر نقطه از زمان جلوگیری می کند.
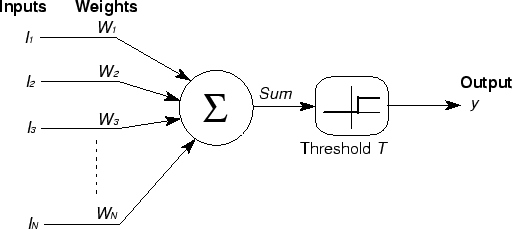
در زیر تصویری از دروازه آستانه خطی توسط کیوشی کاواگوچی آمده است.
قانون یادگیری هبی
در سال 1949، شش سال پس از اختراع مدلهای MCP، دونالد او. هب در تحقیق خود با عنوان ” سازمان رفتار “ مفهوم نورونها را تقویت کرد . به دلیل مشارکت قابل توجهش در یادگیری عمیق، او را پدر شبکه های عصبی نیز می نامند.

حال بیایید ببینیم قانون هبی در مورد چیست. بیان می کند که ارتباط بین دو واحد باید با افزایش فراوانی همزمانی این دو واحد تقویت شود.
برای درک این قانون، در اینجا گزیده ای از کتاب او آورده شده است.
هنگامی که یک آکسون سلول A به اندازه کافی نزدیک است که سلول B را تحریک کند و به طور مکرر یا مداوم در شلیک آن شرکت می کند، برخی از فرآیندهای رشد یا تغییرات متابولیکی در یک یا هر دو سلول رخ می دهد به طوری که به عنوان کارایی، به عنوان یکی از سلول های شلیک کننده B. ، افزایش یافته است.”
بیانیه بالا توضیح می دهد که چگونه فعالیت های عصبی بر ارتباط بین نورون ها، یعنی شکل پذیری سیناپسی تأثیر می گذارد. این یک الگوریتم برای به روز رسانی وزن اتصالات عصبی در شبکه عصبی ارائه می دهد. برای خلاصه کردن تحقیقات او، در اینجا سه نکته مهم از مکانیسم یادگیری هبی وجود دارد:
- اطلاعات بین اتصالات نورون در یک شبکه عصبی به شکل وزن ذخیره می شود.
- به روز رسانی وزن ها به طور مستقیم با محصول مقادیر فعال سازی نورون ها متناسب است.
- همانطور که یادگیری اتفاق می افتد، فعال سازی همزمان یا مکرر نورون های ضعیف به طور تدریجی قدرت و الگو را تغییر می دهد و منجر به اتصالات قوی تر می شود.
پرسپترون
در سال 1957، پس از موفقیت مدل های MCP و قانون هبیان، فرانک روزنبلات، روانشناس، اولین شبکه عصبی قابل آموزش به نام پرسپترون را ارائه کرد . بعدها، او یک دستگاه الکترونیکی از یک پرسپترون ساخت که توانایی یادگیری مطابق با تداعی گرایی را نشان می داد.
طراحی پرسپترون شبیه شبکه عصبی مدرن بود، با این تفاوت که تنها یک لایه دارد که ورودی را به دو دسته خروجی ممکن با وزنها و آستانههای قابل تنظیم، بین لایههای ورودی و خروجی طبقهبندی میکند.

بیشتر تحقیقات او عمدتاً از زمینه بینایی انسان الهام گرفته شده است. بیایید ببینیم چگونه!
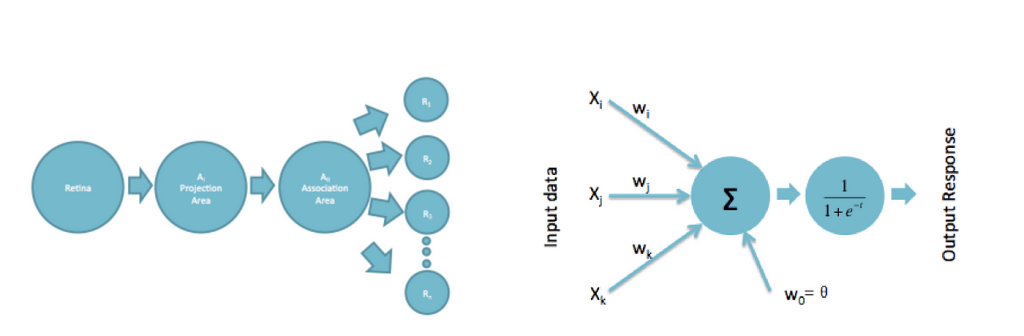
تصویر سمت چپ پرسپترون روزنبلات را توضیح می دهد. دارای چهار واحد، واحد حسی، واحد فرافکنی، واحد تداعی و واحد پاسخ است. هنگامی که ورودی به شبکیه چشم فرستاده می شود، اطلاعات به ناحیه طرح ریزی فرستاده می شود که سپس به واحد حسی منتقل می شود و بعداً به واحد ارتباط منتقل می شود. این ساختار شبیه ساختار پرسپترون امروزی در یک شبکه عصبی است که در سمت راست نشان داده شده است.
پرسپترون را می توان کاملاً شبیه به مدل MCP فرض کرد. با این حال، در اینجا تفاوت های عمده وجود دارد:
در پرسپترون، نورون ها یک ثابت اضافی مرتبط با وزن های سیناپسی به نام بایاس (b) می گیرند. می توان آن را به عنوان نفی آستانه فعال سازی در نظر گرفت.
- وزن های سیناپسی محدود به وحدت یا مثبت نیستند. از این رو، برخی از ورودیها میتوانند تأثیر بازدارندهای داشته باشند، بنابراین به برخی از ورودیها اجازه میدهند بر خروجی نورون بیش از دیگران تأثیر بگذارند.
از نظر ریاضی، غیر خطی بودن نورون مصنوعی که پرسپترون بر آن تکیه دارد، به صورت زیر داده می شود:
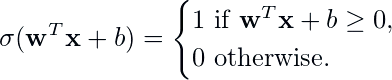
مهم نیست که فرمول چیست، مرز تصمیم برای پرسپترون (و بسیاری از طبقهبندیکنندههای خطی دیگر) توسط:
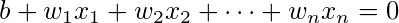
از طرف دیگر، می توانیم یک نماد ریاضی فشرده به صورت زیر ارائه دهیم:
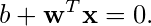
در اینجا یک تصویر مدرن از پرسپترون است که توضیح می دهد چگونه وزن ها و سوگیری ها به نورون ها متصل می شوند:
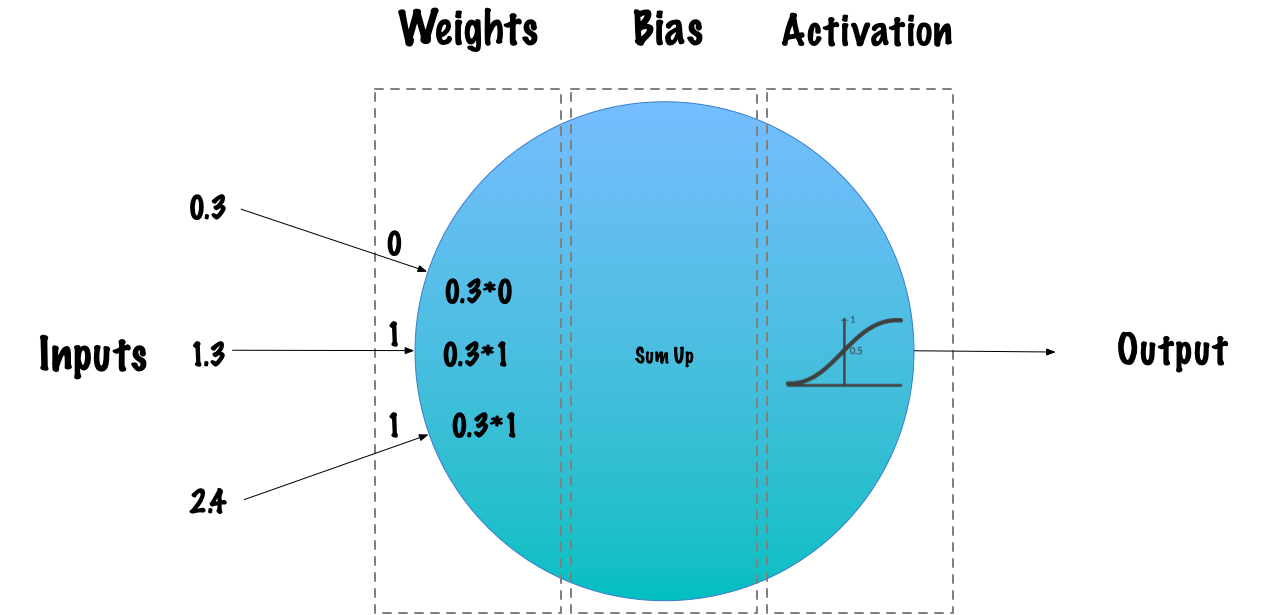
انتشار پشت
تکنیک یادگیری پس انتشار یکی از پیشرفت های مهم در زمینه یادگیری عمیق بود. این الگوریتم در دهه 1970 معرفی شد. با این حال، اهمیت آن تا زمانی که مقاله تحقیقاتی معروف در سال 1986، “یادگیری بازنمایی با خطاهای پس از انتشار”، که توسط دیوید روملهارت، جفری هینتون و رونالد ویلیامز منتشر شد، کاملا درک نشد.

بدون یک روش انتشار پسپشتی کارآمد برای یک شبکه عصبی، آموزش شبکههای یادگیری عمیق تا عمقی که امروزه میبینیم غیرعملی خواهد بود. پس انتشار را می توان به عنوان پایه ای برای شبکه های عصبی مدرن و یادگیری عمیق در نظر گرفت.
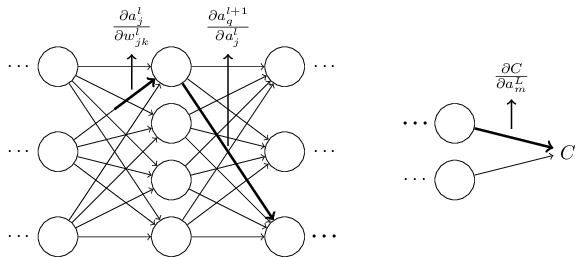
این الگوریتم برای آموزش کارآمد یک شبکه عصبی با استفاده از روشی به نام قانون زنجیره ای استفاده می شود. به عبارت ساده، پس از هر عبور رو به جلو از شبکه، پس انتشار یک پاس به عقب انجام می دهد و در عین حال پارامترهای مدل (وزن ها و بایاس ها) را تنظیم می کند. در قلب انتشار پس زمینه بیانی از مشتق جزئی، ∂C/∂w تابع هزینه، C مربوط به هر وزن، w (یا بایاس b) در شبکه است.
“چرا از مشتقات برای الگوریتم پس انتشار استفاده کنیم؟”
- گرادیان تابع هزینه C برای یک ورودی خاص x بردار مشتقات جزئی C است.
- با استفاده از این گرادیان تابع هزینه، میتوانیم حساسیت مقدار خروجی را نسبت به تغییر مقدار ورودی اندازهگیری کنیم. به عبارت دیگر، با استفاده از این مشتق، میتوانیم جهتی را که تابع هزینه طی میکند، درک کنیم.
- در مجموع، گرادیان نشان می دهد که پارامتر w (یا b) چقدر باید تغییر کند (در جهت مثبت یا منفی) تا C را به حداقل برساند.
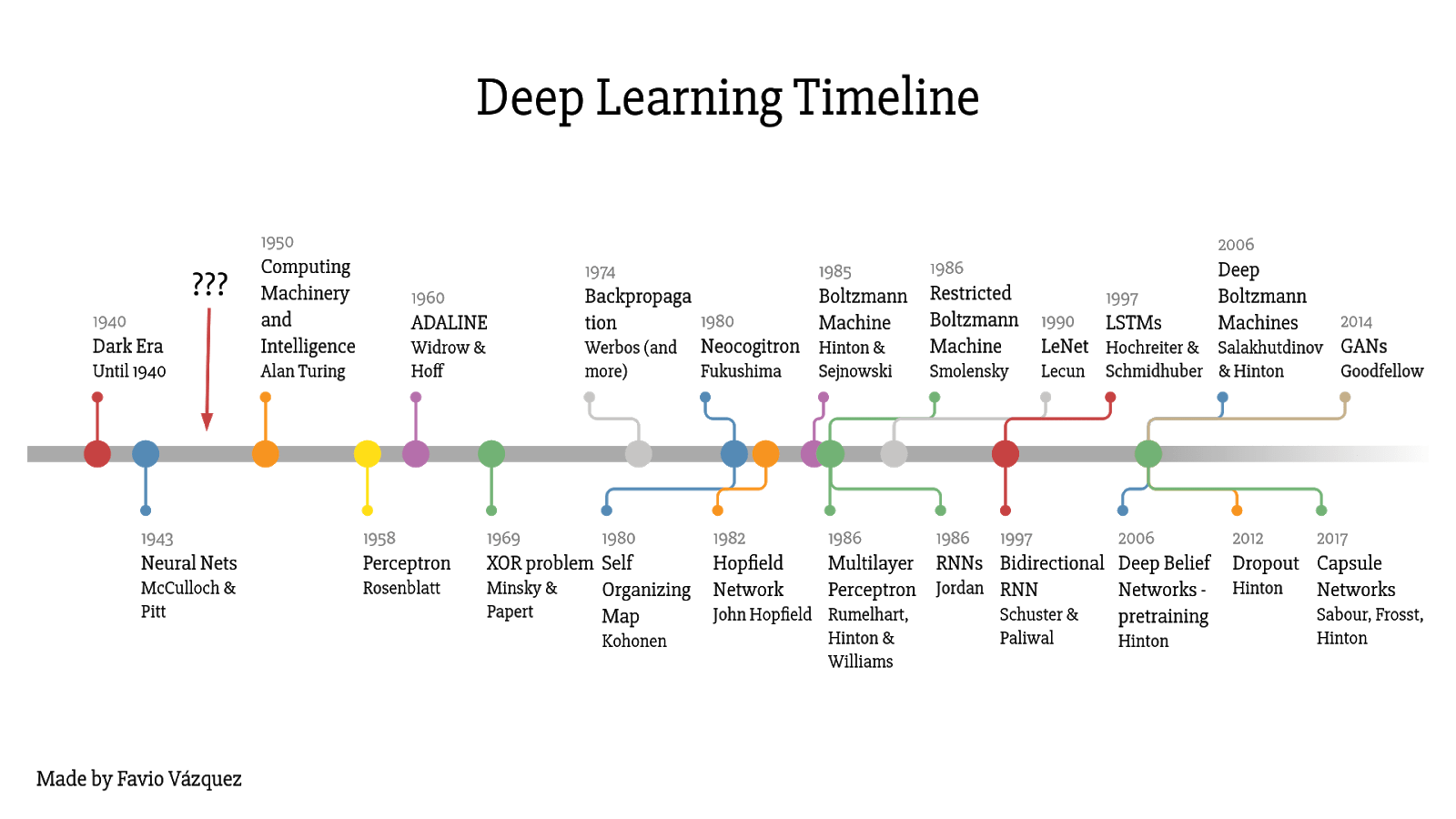
تا کنون، ما شاهد چند مشارکت مهم توسط پیشگامان یادگیری عمیق بودهایم. در زیر تصویری است که به ما یک ایده کلی از چگونگی تکامل این دامنه از دهه 1940 ارائه می دهد. همانطور که می بینیم، جدول زمانی بسیار متراکم است، و پوشش همه اینها در یک پست وبلاگ کاملا غیر واقعی خواهد بود. اگر هنوز علاقه مند به کسب اطلاعات بیشتر در مورد این موضوع هستید، پیشنهاد می کنم این تحقیق خارق العاده با عنوان ” درباره منشاء یادگیری عمیق” توسط هاوهان وانگ و بهیکشا راج را مطالعه کنید.
اکنون، بیایید ببینیم که چگونه یادگیری عمیق در زمینه های مختلف با کاربردهای مربوطه تا به امروز تکامل یافته است.
زمینه ها و کاربردهای یادگیری عمیق
پیشرفت های کنونی در فناوری مدت ها پیش غیر قابل لمس بوده است. ما هرگز یک کامپیوتر انسانی، اتومبیل های خودران و بهبود روش های پزشکی را تصور نکرده ایم. اما امروزه اینها با قدرت یادگیری عمیق بخشی از زندگی روزمره ما شده اند. اکنون اجازه دهید کاربردهای یادگیری عمیق را در مناطق مختلف بیشتر درک کنیم.
Computer Vision : CV، به طور خلاصه، تکنیک هایی را برای کمک به رایانه ها برای “دیدن” و درک محتوای دیجیتال مانند تصاویر و فیلم ها ارائه می دهد. در زیر تعدادی از کاربردهای DL برای کامپیوتر ویژن آورده شده است.
- تشخیص و شناسایی چهره
- تصاویر ماهواره ای و پهپاد
- بهینه سازی جستجوی تصویر
- وضوح تصویر فوق العاده و رنگ آمیزی
- هدایت وسایل نقلیه خودران برای شناسایی جاده، عابران پیاده، چراغ های سیگنال و غیره.
پردازش زبان طبیعی (NLP): NLP به درک پیچیدگی های مرتبط با زبان کمک می کند، می تواند نحوی، معنایی، تفاوت های لحنی، عبارات یا حتی طعنه باشد. با افزایش قدرت محاسباتی، یادگیری عمیق اکنون قادر به شناسایی و درک زبان انسان نیز می باشد. دستیارهای هوش مصنوعی مانند سیری، Google Voice عمدتاً برای پردازش اطلاعات به NLP متکی هستند. در اینجا چند مورد از کاربردهای آن آورده شده است.
- تشخیص گفتار
- شناسایی موجودیت نامگذاری شده (شناسایی نام، مکان، آدرس و ممکن است از متن حرکت کند)
- چت ربات، (سؤال و جواب)
- تشخیص احساسات و عواطف در شبکه های اجتماعی
پزشکی و زیست شناسی: پیشرفت در پزشکی و زیست شناسی، حجم وسیعی از داده ها مانند تصاویر پزشکی، اطلاعات ژن، توالی پروتئین و بسیاری موارد دیگر را فراهم کرده است. با استفاده از این داده ها، چندین الگوریتم مبتنی بر یادگیری عمیق در حال توسعه هستند که به طور گسترده در تولید به پزشکان، دانشمندان و رادیولوژیست ها کمک می کنند. در زیر چند برنامه کاربردی وجود دارد که از طریق DL به موفقیت دست یافتند:
- طبقه بندی تصاویر پزشکی (در تصاویر CT، MRI، اشعه ایکس)
- تقسیم بندی تومور
- تاخوردگی پروتئین و کشف دارو
- پردازش متن بالینی
گیمینگ: DL شیوه بازی های قبلی را متحول کرده است. الگوریتم های DL اکنون می توانند با سازگاری با وضعیت عاطفی و روانی بازیکن، علیه انسان ها بازی کنند. همه از یادگیری تقویتی برای آوردن مفهوم یادگیری با آزمون و خطا سپاسگزاریم.
در زیر چند برنامه کاربردی که به طور گسترده مورد استفاده قرار می گیرند آورده شده است:
- پخش NPC (شخصیت غیرقابل بازی) – روبات
- مدل سازی تعاملات پیچیده
- پردازش گرافیکی ویدیویی
- ایجاد جهان بازی