یادگیری کیو یک رویکرد یادگیری ماشینی است که یک مدل را قادر میسازد تا به طور مکرر یاد بگیرد و با انجام اقدامات صحیح در طول زمان بهبود یابد. یادگیری کیو نوعی یادگیری تقویتی است.
با یادگیری تقویتی، یک مدل یادگیری ماشینی برای تقلید از روش یادگیری حیوانات یا کودکان آموزش داده می شود. اعمال خوب پاداش یا تقویت می شوند، در حالی که اقدامات بد دلسرد و مجازات می شوند.
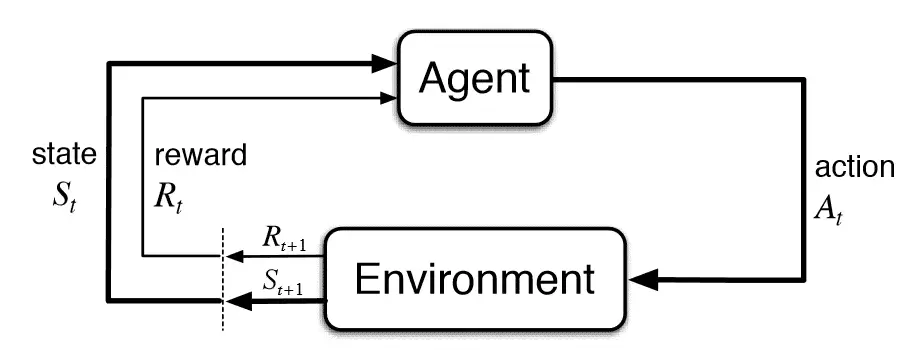
با شکل یادگیری تقویتی حالت-عمل-پاداش-حالت-عمل، رژیم آموزشی از مدلی برای انجام اقدامات درست پیروی می کند. Q-learning یک رویکرد بدون مدل برای یادگیری تقویتی ارائه می دهد. هیچ مدلی از محیط برای هدایت فرآیند یادگیری تقویتی وجود ندارد. عامل – که جزء هوش مصنوعی است که در محیط عمل می کند – بطور مکرر به تنهایی محیط را یاد می گیرد و پیش بینی می کند.
Q-learning همچنین رویکردی خارج از سیاست برای یادگیری تقویتی دارد. هدف یک رویکرد یادگیری Q تعیین عملکرد بهینه بر اساس وضعیت فعلی آن است. رویکرد یادگیری Q می تواند این امر را با توسعه مجموعه قوانین خود یا انحراف از خط مشی تعیین شده انجام دهد. از آنجایی که یادگیری کیو ممکن است از خط مشی داده شده منحرف شود، به یک خط مشی تعریف شده نیازی نیست.
رویکرد خارج از سیاست در یادگیری Q با استفاده از مقادیر Q – که به عنوان ارزش های عمل نیز شناخته می شوند، به دست می آید. Q-values مقادیر مورد انتظار آینده برای عمل هستند و در Q-table ذخیره می شوند.
کریس واتکینز برای اولین بار در مورد پایه های یادگیری Q بحث کرد پایان نامه 1989 برای دانشگاه کمبریج و بیشتر در a انتشار 1992 با عنوان Q-Learning.
یادگیری کیو چگونه کار می کند؟
مدلهای یادگیری Q در یک فرآیند تکراری عمل میکنند که شامل چندین مؤلفه با هم کار میکنند تا به آموزش یک مدل کمک کنند. فرآیند تکراری شامل یادگیری عامل با کاوش در محیط و به روز رسانی مدل در ادامه کاوش است. اجزای متعدد یادگیری Q شامل موارد زیر است:
- عوامل. عامل موجودی است که در یک محیط عمل می کند و عمل می کند.
- ایالت ها. حالت متغیری است که موقعیت فعلی را در محیط یک عامل مشخص می کند.
- اقدامات. عمل زمانی که در یک حالت خاص باشد عملیات عامل است.
- پاداش. یک مفهوم اساسی در یادگیری تقویتی، مفهوم ارائه پاسخ مثبت یا منفی برای اقدامات عامل است.
- اپیزودها اپیزود زمانی است که یک نماینده دیگر نمی تواند اقدام جدیدی انجام دهد و در نهایت به پایان می رسد.
- مقادیر Q Q-value معیاری است که برای اندازه گیری یک عمل در یک وضعیت خاص استفاده می شود.
در اینجا دو روش برای تعیین مقدار Q وجود دارد:
- تفاوت زمانی فرمول تفاوت زمانی، Q-value را با ترکیب مقدار وضعیت فعلی و عملکرد با مقایسه تفاوتها با حالت و عملکرد قبلی محاسبه میکند.
- معادله بلمن ریچارد بلمن ریاضیدان این معادله را در سال 1957 به عنوان فرمولی بازگشتی برای تصمیم گیری بهینه اختراع کرد. در زمینه یادگیری q، از معادله بلمن برای کمک به محاسبه مقدار یک حالت معین و ارزیابی موقعیت نسبی آن استفاده می شود. حالتی که بالاترین مقدار را دارد حالت بهینه در نظر گرفته می شود.
مدلهای یادگیری Q از طریق تجربیات آزمون و خطا کار میکنند تا رفتار بهینه برای یک کار را بیاموزند. فرآیند یادگیری Q شامل مدل سازی رفتار بهینه با یادگیری یک تابع ارزش عمل بهینه یا تابع q است. این تابع مقدار بهینه دراز مدت عمل a را در حالت s نشان می دهد و متعاقباً در هر حالت بعدی رفتار بهینه را دنبال می کند.
Q-table چیست؟
جدول Q شامل ستونها و ردیفهایی با فهرستهایی از پاداشها برای بهترین اقدامات هر ایالت در یک محیط خاص است. یک جدول Q به یک عامل کمک می کند تا بفهمد چه اقداماتی احتمالاً در موقعیت های مختلف منجر به نتایج مثبت می شود.
ردیفهای جدول موقعیتهای مختلفی را نشان میدهند که ممکن است عامل با آن مواجه شود، و ستونها نشاندهنده اقداماتی هستند که میتواند انجام دهد. همانطور که عامل با محیط تعامل می کند و بازخوردی را به شکل پاداش یا جریمه دریافت می کند، مقادیر در جدول Q به روز می شوند تا آنچه را که مدل آموخته است منعکس کند.
هدف از یادگیری تقویتی بهبود تدریجی عملکرد از طریق جدول Q برای کمک به انتخاب اقدامات است. با بازخورد بیشتر، جدول Q دقیق تر می شود تا نماینده بتواند تصمیمات بهتری بگیرد و به نتایج مطلوب دست یابد.
جدول Q ارتباط مستقیمی با مفهوم تابع Q دارد. تابع Q یک معادله ریاضی است که به وضعیت فعلی محیط و عمل مورد بررسی به عنوان ورودی نگاه می کند. سپس تابع Q خروجی هایی را به همراه پاداش های مورد انتظار آینده برای آن اقدام در حالت خاص تولید می کند. جدول Q به عامل اجازه می دهد تا پاداش آینده مورد انتظار را برای هر جفت حالت-عمل معین برای حرکت به سمت یک حالت بهینه جستجو کند.
فرآیند الگوریتم یادگیری Q چیست؟
فرآیند الگوریتم یادگیری Q یک روش تعاملی است که در آن عامل با کاوش در محیط و به روز رسانی جدول Q بر اساس پاداش های دریافتی، یاد می گیرد.
مراحل درگیر در فرآیند الگوریتم یادگیری Q شامل موارد زیر است:
- مقداردهی اولیه جدول Q اولین قدم ایجاد جدول Q به عنوان مکانی برای ردیابی هر عمل در هر حالت و پیشرفت مرتبط است.
- مشاهده عامل باید وضعیت فعلی محیط را مشاهده کند.
- عمل. عامل انتخاب می کند که در محیط عمل کند. پس از اتمام عمل، مدل مشاهده می کند که آیا عمل در محیط مفید است یا خیر.
- به روز رسانی. پس از انجام اقدامات، زمان به روز رسانی جدول Q با نتایج است.
- تکرار. مراحل 2-4 را تکرار کنید تا مدل به حالت پایان برای یک هدف مورد نظر برسد.
مزایای Q-learning چیست؟
رویکرد یادگیری Q برای یادگیری تقویتی می تواند به دلایل مختلف از جمله موارد زیر سودمند باشد:
- بدون مدل. رویکرد بدون مدل پایه و اساس یادگیری Q و یکی از بزرگترین مزایای بالقوه برای برخی از کاربردها است. به جای نیاز به دانش قبلی در مورد یک محیط، عامل یادگیری Q می تواند در حین آموزش در مورد محیط بیاموزد. رویکرد بدون مدل به ویژه برای سناریوهایی که مدلسازی دینامیک زیربنایی یک محیط دشوار است یا کاملاً ناشناخته است، مفید است.
- بهینه سازی خارج از سیاست این مدل میتواند بهینهسازی شود تا بهترین نتیجه ممکن را به دست آورد، بدون اینکه به شدت به سیاستی وابسته باشد که ممکن است درجه یکسانی از بهینهسازی را فعال نکند.
- انعطاف پذیری رویکرد بدون مدل و خارج از سیاست، انعطافپذیری یادگیری Q را قادر میسازد تا در انواع مشکلات و محیطها کار کند.
- آموزش آفلاین. یک مدل یادگیری Q می تواند بر روی مجموعه داده های از پیش جمع آوری شده و آفلاین مستقر شود.
معایب Q-learning چیست؟
رویکرد یادگیری Q برای یادگیری ماشینی مدل تقویتی نیز دارای معایبی است، مانند موارد زیر:
- معاوضه اکتشاف در مقابل بهره برداری. برای یک مدل یادگیری Q یافتن تعادل مناسب بین تلاش برای اقدامات جدید و پایبندی به آنچه قبلاً شناخته شده است دشوار است. این معضلی است که معمولاً از آن به عنوان مبادله اکتشاف در مقابل بهره برداری برای یادگیری تقویتی یاد می شود.
- نفرین ابعاد. یادگیری کیو به طور بالقوه می تواند با خطر یادگیری ماشینی به نام نفرین ابعادی مواجه شود. نفرین ابعاد یک مشکل با داده های با ابعاد بالا است که در آن مقدار داده مورد نیاز برای نمایش توزیع به طور تصاعدی افزایش می یابد. این می تواند منجر به چالش های محاسباتی و کاهش دقت شود.
- بیش از حد. یک مدل یادگیری Q گاهی اوقات می تواند خیلی خوش بینانه باشد و میزان خوب بودن یک اقدام یا استراتژی خاص را بیش از حد تخمین بزند.
- کارایی. در صورتی که چندین راه برای نزدیک شدن به یک مشکل وجود داشته باشد، یک مدل یادگیری Q می تواند زمان زیادی طول بکشد تا بهترین روش را کشف کند.
چند نمونه از یادگیری Q چیست؟
مدل های یادگیری Q می توانند فرآیندها را در سناریوهای مختلف بهبود بخشند. در اینجا چند نمونه از کاربردهای یادگیری Q آمده است:
- مدیریت انرژی. مدلهای یادگیری Q به مدیریت انرژی برای منابع مختلف مانند برق، گاز و آب کمک میکنند. آ گزارش 2022 از IEEE یک رویکرد دقیق برای ادغام یک مدل یادگیری Q برای مدیریت انرژی ارائه می دهد.
- دارایی، مالیه، سرمایه گذاری. یک مدل آموزشی مبتنی بر یادگیری Q میتواند مدلهایی را برای کمک در تصمیمگیری، مانند تعیین لحظات بهینه برای خرید یا فروش دارایی، بسازد.
- بازی مدلهای یادگیری کیو میتوانند سیستمهای بازی را برای دستیابی به سطح کارشناسی مهارت در انجام طیف وسیعی از بازیها آموزش دهند، زیرا مدل استراتژی بهینه برای پیشرفت را میآموزد.
- سیستم های توصیه مدلهای یادگیری Q میتوانند به بهینهسازی سیستمهای توصیه، مانند پلتفرمهای تبلیغاتی کمک کنند. برای مثال، یک سیستم تبلیغاتی که محصولاتی را که معمولاً با هم خریداری میشوند را توصیه میکند، میتواند بر اساس انتخاب کاربران بهینه شود.
- رباتیک. مدلهای یادگیری Q میتوانند به آموزش روباتها برای اجرای وظایف مختلف مانند دستکاری اشیا، اجتناب از موانع و حمل و نقل کمک کنند.
- ماشین های خودران. وسایل نقلیه خودران از مدلهای مختلفی استفاده میکنند، و مدلهای یادگیری Q به آموزش مدلها کمک میکنند تا تصمیمگیری در مورد رانندگی، مانند زمان تعویض خط یا توقف، به مدلها کمک کنند.
- مدیریت زنجیره تامین جریان کالاها و خدمات به عنوان بخشی از مدیریت زنجیره تامین را می توان با مدل های یادگیری Q بهبود بخشید تا به یافتن مسیر بهینه برای محصولات به بازار کمک کند.
آموزش کیو با پایتون
پایتون یکی از رایج ترین زبان های برنامه نویسی برای یادگیری ماشین است. افراد مبتدی و متخصص معمولاً از پایتون برای استفاده از مدل های یادگیری Q استفاده می کنند. برای یادگیری Q و هر عملیات علم داده در پایتون، کاربران به پایتون نیاز دارند تا روی سیستمی با NumPy کتابخانه (Python عددی) که از توابع ریاضی برای استفاده با هوش مصنوعی پشتیبانی می کند.
با Python و NumPy، مدلهای یادگیری Q با چند مرحله اساسی تنظیم میشوند:
- محیط را تعریف کنید. متغیرهایی برای حالت ها و اقدامات برای تعریف محیط ایجاد کنید.
- Q-table را راه اندازی کنید. شرط اولیه جدول Q روی صفر تنظیم شده است.
- تنظیم هایپرپارامترها پارامترهایی را در پایتون تنظیم کنید تا تعداد قسمت ها، میزان یادگیری و اکتشاف را مشخص کنید.
- الگوریتم یادگیری Q را اجرا کنید. عامل یک عمل را به صورت تصادفی یا بر اساس بالاترین مقدار Q برای وضعیت فعلی انتخاب می کند. پس از انجام اقدام، جدول Q با نتایج به روز می شود.
برنامه یادگیری کیو
قبل از استفاده از مدل یادگیری Q، مهم است که ابتدا مشکل را درک کنید و چگونه آموزش یادگیری Q را می توان برای آن مشکل به کار برد.
Q-learning را در پایتون با یک ویرایشگر کد استاندارد یا یک محیط توسعه یکپارچه برای نوشتن کد راه اندازی کنید. برای اعمال و آزمایش یک مدل یادگیری Q، از ابزار یادگیری ماشینی مانند بنیاد فراما استفاده کنید ورزشگاه. سایر ابزارهای رایج عبارتند از چارچوب برنامه کاربردی یادگیری ماشین PyTorch منبع باز برای پشتیبانی از جریان کار یادگیری تقویتی از جمله یادگیری Q.