مدل زبان بزرگ (LLM) نوعی الگوریتم هوش مصنوعی (AI) است که از تکنیکهای یادگیری عمیق و مجموعه دادههای بسیار بزرگ برای درک، خلاصهسازی، تولید و پیشبینی محتوای جدید استفاده میکند. اصطلاح هوش مصنوعی مولد نیز ارتباط نزدیکی با LLM دارد که در واقع نوعی از هوش مصنوعی مولد است که به طور خاص برای کمک به تولید محتوای متنی طراحی شده است.
در طول هزاران سال، انسان ها زبان های گفتاری را برای برقراری ارتباط توسعه دادند. زبان هسته اصلی همه اشکال ارتباطات انسانی و فناوری است. واژگان، معناشناسی و دستور زبان مورد نیاز برای انتقال ایده ها و مفاهیم را فراهم می کند. در دنیای هوش مصنوعی، یک مدل زبان هدف مشابهی را دنبال میکند و مبنایی برای برقراری ارتباط و تولید مفاهیم جدید فراهم میکند.
اولین مدل های زبان هوش مصنوعی ریشه در اولین روزهای هوش مصنوعی دارند. مدل زبان ELIZA در سال 1966 در MIT معرفی شد و یکی از اولین نمونه های یک مدل زبان هوش مصنوعی است. همه مدلهای زبان ابتدا بر روی مجموعهای از دادهها آموزش داده میشوند و سپس از تکنیکهای مختلف برای استنباط روابط و سپس تولید محتوای جدید بر اساس دادههای آموزشدیده استفاده میکنند. مدلهای زبان معمولاً در برنامههای پردازش زبان طبیعی (NLP) استفاده میشوند که در آن کاربر یک پرس و جو را به زبان طبیعی برای ایجاد نتیجه وارد میکند.
LLM تکامل مفهوم مدل زبان در هوش مصنوعی است که به طور چشمگیری داده های مورد استفاده برای آموزش و استنتاج را گسترش می دهد. به نوبه خود، افزایش گسترده ای در قابلیت های مدل هوش مصنوعی ایجاد می کند. در حالی که یک رقم قابل قبول جهانی برای اینکه مجموعه داده برای آموزش چقدر باید باشد وجود ندارد، یک LLM معمولا حداقل یک میلیارد یا بیشتر پارامتر دارد. پارامترها یک اصطلاح یادگیری ماشینی برای متغیرهای موجود در مدلی است که بر اساس آن آموزش داده شده است که می تواند برای استنباط محتوای جدید استفاده شود.
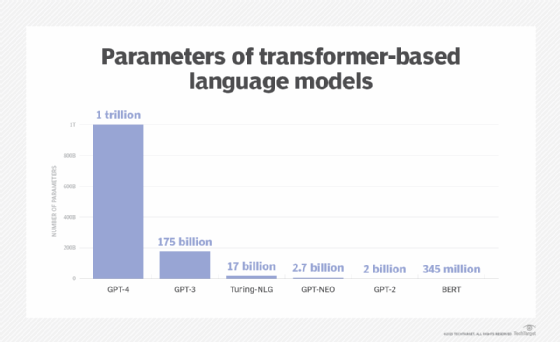
GPT-4، یک LLM، از نظر تعداد پارامترهای خود، همه پیشینیان را کوتوله می کند.
LLM های مدرن در سال 2017 ظهور کردند و از شبکه های عصبی ترانسفورماتور استفاده می کنند که معمولاً ترانسفورماتور نامیده می شود. با تعداد زیادی پارامتر و مدل ترانسفورماتور، LLM ها قادر به درک و ایجاد پاسخ های دقیق به سرعت هستند، که باعث می شود فناوری هوش مصنوعی به طور گسترده در بسیاری از حوزه های مختلف قابل استفاده باشد.
برخی از LLM ها به عنوان مدل های پایه نامیده می شوند، اصطلاحی که توسط موسسه استنفورد برای هوش مصنوعی انسان محور در سال 2021 ابداع شد.
مدل های زبان بزرگ چگونه کار می کنند؟
LLM ها رویکرد پیچیده ای دارند که شامل چندین مؤلفه است.
در لایه بنیادی، یک LLM باید بر روی حجم زیادی از دادههایی که معمولاً اندازه پتابایت است، آموزش ببیند – که گاهی اوقات به عنوان یک پیکره نامیده میشود. آموزش می تواند مراحل متعددی را طی کند که معمولاً با رویکرد یادگیری بدون نظارت شروع می شود. در آن رویکرد، مدل بر روی داده های بدون ساختار و داده های بدون برچسب آموزش داده می شود. مزیت آموزش در مورد داده های بدون برچسب این است که اغلب داده های بسیار بیشتری در دسترس است. در این مرحله، مدل شروع به استخراج روابط بین کلمات و مفاهیم مختلف می کند.
گام بعدی برای برخی از LLM ها آموزش و تنظیم دقیق با نوعی یادگیری تحت نظارت است. در اینجا، برخی از برچسبگذاری دادهها رخ داده است که به مدل کمک میکند تا مفاهیم مختلف را با دقت بیشتری شناسایی کند.
در مرحله بعد، LLM همزمان با گذر از فرآیند شبکه عصبی ترانسفورماتور، یادگیری عمیق را بر عهده می گیرد. معماری ترانسفورماتور LLM را قادر می سازد تا روابط و ارتباطات بین کلمات و مفاهیم را با استفاده از مکانیزم توجه به خود درک و تشخیص دهد. آن مکانیسم قادر است برای تعیین رابطه، امتیازی را که معمولاً به عنوان وزن از آن یاد می شود، به یک آیتم معین (که نشانه نامیده می شود) اختصاص دهد.
هنگامی که یک LLM آموزش داده شد، پایگاهی وجود دارد که بر اساس آن می توان از هوش مصنوعی برای اهداف عملی استفاده کرد. با پرس و جو از LLM با یک اعلان، استنتاج مدل هوش مصنوعی می تواند پاسخی را ایجاد کند که می تواند پاسخی به یک سوال، متن تازه تولید شده، متن خلاصه شده یا تجزیه و تحلیل احساسات باشد.
مدل های زبان بزرگ برای چه مواردی استفاده می شوند؟
LLM ها به طور فزاینده ای محبوب شده اند زیرا کاربرد گسترده ای برای طیف وسیعی از وظایف NLP از جمله موارد زیر دارند:
- تولید متن توانایی تولید متن در مورد هر موضوعی که LLM در مورد آن آموزش دیده است، یک مورد استفاده اولیه است.
- ترجمه. برای LLM هایی که در چندین زبان آموزش دیده اند، توانایی ترجمه از یک زبان به زبان دیگر یک ویژگی مشترک است.
- خلاصه مطالب. خلاصه کردن بلوک ها یا چندین صفحه متن یک عملکرد مفید LLM است.
- بازنویسی مطالب بازنویسی یک قسمت از متن یکی دیگر از قابلیت های آن است.
- طبقه بندی و طبقه بندی. یک LLM قادر به طبقه بندی و طبقه بندی محتوا است.
- تحلیل احساسات اکثر LLM ها می توانند برای تجزیه و تحلیل احساسات استفاده شوند تا به کاربران کمک کنند تا هدف یک محتوا یا یک پاسخ خاص را بهتر درک کنند.
- هوش مصنوعی مکالمه و چت بات ها. LLM ها می توانند مکالمه با کاربر را به گونه ای فعال کنند که معمولاً طبیعی تر از نسل های قدیمی فناوری های هوش مصنوعی است.
یکی از رایجترین کاربردهای هوش مصنوعی مکالمه، استفاده از ربات چت است که میتواند به شکلهای مختلفی وجود داشته باشد که در آن کاربر در یک مدل پرسش و پاسخ تعامل دارد. یکی از پرکاربردترین رباتهای چت هوش مصنوعی مبتنی بر LLM، ChatGPT است که مبتنی بر مدل GPT-3 OpenAI است.
مزایای مدل های زبان بزرگ چیست؟
مزایای متعددی وجود دارد که LLM برای سازمان ها و کاربران ارائه می کند:
- توسعه پذیری و سازگاری. LLM ها می توانند به عنوان پایه ای برای موارد استفاده سفارشی عمل کنند. آموزش اضافی در بالای یک LLM می تواند یک مدل دقیق تنظیم شده برای نیازهای خاص یک سازمان ایجاد کند.
- انعطاف پذیری One LLM می تواند برای بسیاری از وظایف و استقرارهای مختلف در سازمان ها، کاربران و برنامه ها استفاده شود.
- کارایی. LLM های مدرن معمولاً عملکرد بالایی دارند و توانایی ایجاد پاسخ های سریع و کم تاخیر را دارند.
- دقت. همانطور که تعداد پارامترها و حجم داده های آموزش دیده در یک LLM افزایش می یابد، مدل ترانسفورماتور قادر است سطوح بالایی از دقت را ارائه دهد.
- سهولت در آموزش. بسیاری از LLM ها بر روی داده های بدون برچسب آموزش می بینند که به تسریع روند آموزش کمک می کند.
چالش ها و محدودیت های مدل های زبان بزرگ چیست؟
در حالی که استفاده از LLM مزایای زیادی دارد، چالش ها و محدودیت های متعددی نیز وجود دارد:
- هزینه های توسعه برای اجرا، LLM ها معمولاً به مقادیر زیادی سخت افزار واحد پردازش گرافیکی گران قیمت و مجموعه داده های عظیم نیاز دارند.
- هزینه های عملیاتی پس از دوره آموزش و توسعه، هزینه راه اندازی LLM برای سازمان میزبان می تواند بسیار بالا باشد.
- جانبداری. خطری که با هر هوش مصنوعی آموزش دیده بر روی داده های بدون برچسب وجود دارد، سوگیری است، زیرا همیشه روشن نیست که سوگیری شناخته شده حذف شده است.
- قابل توضیح توانایی توضیح اینکه چگونه یک LLM توانست یک نتیجه خاص ایجاد کند برای کاربران آسان یا واضح نیست.
- توهم. توهم هوش مصنوعی زمانی اتفاق میافتد که یک LLM پاسخی نادرست ارائه میدهد که مبتنی بر دادههای آموزشدیده نیست.
- پیچیدگی. با میلیاردها پارامتر، LLM های مدرن فناوری های فوق العاده پیچیده ای هستند که عیب یابی می تواند بسیار پیچیده باشد.
- نشانه های اشکال. اعلانهایی که به طور مخرب طراحی شدهاند و باعث اختلال در عملکرد یک LLM میشوند، به نام نشانههای glitch شناخته میشوند، بخشی از یک روند در حال ظهور از سال 2022 است.
انواع مختلف مدل های زبان بزرگ چیست؟
مجموعه ای از اصطلاحات در حال تکامل برای توصیف انواع مختلف مدل های زبان بزرگ وجود دارد. از انواع متداول می توان به موارد زیر اشاره کرد:
- مدل صفر شات. این یک مدل بزرگ و تعمیمیافته است که بر روی مجموعهای از دادههای عمومی آموزش داده شده است که میتواند نتایج نسبتاً دقیقی را برای موارد استفاده عمومی، بدون نیاز به آموزش اضافی ارائه دهد. GPT-3 اغلب یک مدل شات صفر در نظر گرفته می شود.
- مدلهای تنظیمشده یا مختص دامنه. آموزش اضافی در بالای مدل صفر شات مانند GPT-3 می تواند منجر به یک مدل دقیق و خاص دامنه شود. یک مثال OpenAI Codex است، یک LLM مخصوص دامنه برای برنامه نویسی مبتنی بر GPT-3.
- مدل بازنمایی زبان یکی از نمونههای مدل بازنمایی زبان، بازنمایی رمزگذار دوطرفه از ترانسفورماتورها (BERT) است که از یادگیری عمیق و ترانسفورماتورها برای NLP مناسب استفاده میکند.
- مدل چندوجهی در ابتدا LLM ها به طور خاص فقط برای متن تنظیم می شدند، اما با رویکرد چندوجهی می توان هم متن و هم تصاویر را مدیریت کرد. نمونه ای از این GPT-4 است.
آینده مدل های زبان بزرگ
آینده LLM هنوز توسط انسان هایی نوشته می شود که در حال توسعه این فناوری هستند، اگرچه ممکن است آینده ای وجود داشته باشد که LLM ها خودشان نیز در آن بنویسند. نسل بعدی LLM ها احتمالاً هوش عمومی مصنوعی یا هوشیار به هر معنی کلمه نخواهند بود، اما به طور مداوم بهبود می یابند و «هوشمندتر» می شوند.
LLM ها همچنان بر روی مجموعه های بزرگتری از داده ها آموزش می بینند و این داده ها به طور فزاینده ای برای دقت و سوگیری احتمالی بهتر فیلتر می شوند. همچنین این احتمال وجود دارد که LLM های آینده نسبت به نسل فعلی کار بهتری را در زمینه ارائه اسناد و توضیحات بهتر برای نحوه ایجاد یک نتیجه معین انجام دهند.

فعال کردن اطلاعات دقیق تر برای دانش خاص دامنه، یکی دیگر از مسیرهای احتمالی آینده برای LLM است. همچنین دستهای از LLMها بر اساس مفهومی به نام بازیابی دانش وجود دارد – از جمله REALM گوگل (مدل زبان تقویتشده بازیابی) – که آموزش و استنتاج بر روی مجموعهای از دادهها را امکانپذیر میسازد، دقیقاً مانند آنچه یک کاربر امروزی میتواند به طور خاص محتوا را در یک سایت جستجو کنید.
همچنین کار مداومی برای بهینه سازی اندازه کلی و زمان آموزشی مورد نیاز برای LLM ها، از جمله LLaMA متا (مدل متا AI مدل زبان بزرگ)، که کوچکتر از GPT-3 است، وجود دارد، اگرچه حامیان آن ادعا می کنند که می تواند دقیق تر باشد.
آنچه محتمل است این است که آینده LLMها همچنان روشن باقی خواهد ماند زیرا این فناوری به روش هایی که به بهبود بهره وری انسان کمک می کند به تکامل می رسد.