مدل ترانسفورماتور چیست؟
مدل ترانسفورماتور یک معماری شبکه عصبی است که می تواند به طور خودکار یک نوع ورودی را به نوع دیگری از خروجی تبدیل کند. این اصطلاح در مقاله گوگل در سال 2017 ابداع شد که راهی برای آموزش شبکه عصبی برای ترجمه انگلیسی به فرانسوی با دقت بیشتر و یک چهارم زمان آموزش شبکه های عصبی دیگر پیدا کرد.
این تکنیک بیش از آنچه نویسندگان تصور میکردند قابل تعمیم بود و ترانسفورماتورها در تولید متن، تصاویر و دستورالعملهای روبات استفاده میشوند. همچنین میتواند روابط بین حالتهای مختلف داده، به نام هوش مصنوعی چندوجهی، را برای تبدیل دستورالعملهای زبان طبیعی به تصاویر یا دستورالعملهای روبات مدلسازی کند.
ترانسفورماتورها در همه برنامه های کاربردی مدل زبان بزرگ (LLM) از جمله ChatGPT، جستجوی Google، Dall-E و Microsoft Copilot بسیار مهم هستند.
تقریباً همه برنامههایی که از پردازش زبان طبیعی استفاده میکنند، اکنون از ترانسفورماتورهای زیر هود استفاده میکنند، زیرا عملکرد بهتری نسبت به روشهای قبلی دارند. محققان همچنین کشف کردهاند که مدلهای ترانسفورماتور میتوانند کار با ساختارهای شیمیایی، پیشبینی تاخوردگی پروتئین و تجزیه و تحلیل دادههای پزشکی را در مقیاس بیاموزند.
یکی از جنبههای اساسی ترانسفورماتورها این است که چگونه از مفهوم هوش مصنوعی به نام توجه برای تأکید بر وزن کلمات مرتبط استفاده میکنند که میتواند به رنگ آمیزی متن برای یک کلمه یا نشانه برای توصیف برخی دیگر از دادهها – مانند بخشی از یک تصویر کمک کند. یا ساختار پروتئین — یا واج گفتار.
مفهوم توجه از دهه 1990 به عنوان یک تکنیک پردازش مطرح شده است. با این حال، در سال 2017، تیمی از کارگران گوگل پیشنهاد کردند که می توانند از توجه برای رمزگذاری مستقیم معنای کلمات و ساختار یک زبان خاص استفاده کنند. این انقلابی بود زیرا جایگزین آنچه قبلاً نیاز به یک مرحله رمزگذاری اضافی با استفاده از یک شبکه عصبی اختصاصی داشت. همچنین راهی را برای مدلسازی هر نوع اطلاعاتی باز کرد و راه را برای پیشرفتهای خارقالعادهای که در چند سال گذشته پدیدار شده بود هموار کرد.
مدل ترانسفورماتور چه کاری می تواند انجام دهد؟
ترانسفورماتورها به تدریج محبوبترین انواع معماری شبکههای عصبی یادگیری عمیق را در بسیاری از کاربردها، از جمله شبکههای عصبی بازگشتی (RNN) و شبکههای عصبی کانولوشنال (CNN) غصب میکنند. RNN ها برای پردازش جریان های داده مانند گفتار، جملات و کد ایده آل بودند. اما آنها فقط می توانستند رشته های کوتاه تری را در یک زمان پردازش کنند. تکنیکهای جدیدتر، مانند حافظه کوتاهمدت، رویکردهای RNN بودند که میتوانستند رشتههای طولانیتری را پشتیبانی کنند، اما همچنان محدود و کند بودند. در مقابل، ترانسفورماتورها می توانند سری های طولانی تری را پردازش کنند، و می توانند هر کلمه یا نشانه را به صورت موازی پردازش کنند، که به آنها امکان می دهد مقیاس کارآمدتری داشته باشند.
CNN ها برای پردازش داده ها ایده آل هستند، مانند تجزیه و تحلیل چندین ناحیه از یک عکس به صورت موازی برای شباهت در ویژگی هایی مانند خطوط، شکل ها و بافت ها. این شبکه ها برای مقایسه مناطق مجاور بهینه شده اند. مدلهای ترانسفورماتور، مانند Vision Transformer که در سال 2021 معرفی شد، در مقایسه با مناطقی که ممکن است از یکدیگر دور باشند، در مقایسه با یکدیگر به نظر میرسد عملکرد بهتری دارند. ترانسفورماتورها همچنین کار با داده های بدون برچسب را بهتر انجام می دهند.
ترانسفورماتورها می توانند یاد بگیرند که به طور موثر معنای یک متن را با تجزیه و تحلیل حجم های بزرگتر از داده های بدون برچسب نشان دهند. این به محققان اجازه می دهد تا ترانسفورماتورها را برای پشتیبانی از صدها میلیارد و حتی تریلیون ها ویژگی تغییر دهند. در عمل، مدل های از پیش آموزش دیده ایجاد شده با داده های بدون برچسب تنها به عنوان نقطه شروعی برای اصلاح بیشتر برای یک کار خاص با داده های برچسب دار عمل می کنند. با این حال، این قابل قبول است زیرا مرحله ثانویه به تخصص و قدرت پردازش کمتری نیاز دارد.
معماری مدل ترانسفورماتور
معماری ترانسفورماتور از یک رمزگذار و رمزگشا تشکیل شده است که با هم کار می کنند. مکانیسم توجه به ترانسفورماتورها اجازه می دهد تا معنای کلمات را بر اساس اهمیت تخمین زده شده سایر کلمات یا نشانه ها رمزگذاری کنند. این ترانسفورماتورها را قادر میسازد تا تمام کلمات یا نشانهها را به صورت موازی برای عملکرد سریعتر پردازش کنند و به رشد LLMهای بزرگتر کمک کند.
به لطف مکانیسم توجه، بلوک رمزگذار هر کلمه یا نشانه را به بردارهایی تبدیل می کند که با کلمات دیگر وزن بیشتری دارند. به عنوان مثال، در دو جمله زیر، به دلیل تغییر کلمه پر شده به خالی، وزن معنای آن متفاوت است:
- پارچ را در فنجان ریخت و پر کرد.
- پارچ را در جام ریخت و آن را خالی کرد.
مکانیسم توجه آن را به فنجانی که در جمله اول پر می شود و در جمله دوم به پارچ که در حال خالی شدن است وصل می کند.
رمزگشا اساساً فرآیند را در حوزه هدف معکوس می کند. مورد استفاده اصلی ترجمه انگلیسی به فرانسوی بود، اما همین مکانیسم میتوانست سوالات و دستورالعملهای انگلیسی کوتاه را به پاسخهای طولانیتر تبدیل کند. برعکس، میتواند یک مقاله طولانیتر را به خلاصهای مختصرتر تبدیل کند.
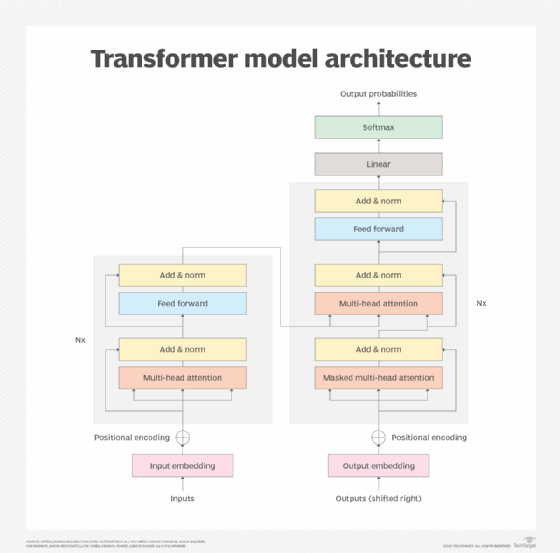
معماری مدل ترانسفورماتور.
آموزش مدل ترانسفورماتور
دو مرحله کلیدی در آموزش ترانسفورماتور وجود دارد. در مرحله اول، یک ترانسفورماتور حجم بزرگی از دادههای بدون برچسب را پردازش میکند تا ساختار زبان یا پدیدهای مانند تا شدن پروتئین و اینکه چگونه عناصر نزدیک به نظر بر یکدیگر تأثیر میگذارند را بیاموزد. این یک جنبه پرهزینه و انرژی بر فرآیند است. ممکن است برای آموزش برخی از بزرگترین مدل ها میلیون ها دلار هزینه شود.
هنگامی که مدل آموزش داده شد، تنظیم دقیق آن برای یک کار خاص مفید است. یک شرکت فناوری ممکن است بخواهد یک ربات چت را تنظیم کند تا به سوالات مختلف خدمات مشتری و پشتیبانی فنی با سطوح مختلف جزئیات بسته به دانش کاربر پاسخ دهد. یک شرکت حقوقی ممکن است مدلی را برای تجزیه و تحلیل قراردادها تنظیم کند. یک تیم توسعه ممکن است مدل را با کتابخانه گسترده کد و قراردادهای کدگذاری منحصر به فرد خود تنظیم کند.
فرآیند تنظیم دقیق به تخصص و قدرت پردازشی کمتری نیاز دارد. طرفداران ترانسفورماتورها استدلال می کنند که هزینه های زیادی که برای آموزش مدل های همه منظوره بزرگتر صرف می شود می تواند نتیجه دهد زیرا باعث صرفه جویی در زمان و هزینه در سفارشی سازی مدل برای موارد مختلف استفاده می شود.
از تعداد ویژگیهای یک مدل بهجای معیارهای برجستهتر، گاهی اوقات بهعنوان پراکسی برای عملکرد آن استفاده میشود. با این حال، تعداد ویژگی ها – یا اندازه مدل – به طور مستقیم با عملکرد یا ابزار کالیبره نمی شود. به عنوان مثال، گوگل اخیراً با استفاده از تکنیک ترکیبی از متخصصان که تقریباً هفت برابر کارآمدتر از سایر مدل ها است، آموزش کارآمدتر LLM ها را آزمایش کرد. اگرچه برخی از این مدلهای حاصل بیش از یک تریلیون پارامتر داشتند، اما دقت کمتری نسبت به مدلهایی با پارامترهای صدها برابر کمتر داشتند.
با این حال، متا اخیراً گزارش داد که متا AI مدل زبان بزرگ (Llama) با 13 میلیارد پارامتر نسبت به مدل ترانسفورماتور از پیش آموزشدیده (GPT) 175 میلیارد پارامتری در معیارهای اصلی عملکرد بهتری داشت. یک نوع 65 میلیارد پارامتری از Llama با عملکرد مدل هایی با بیش از 500 میلیارد پارامتر مطابقت داشت.
برنامه های کاربردی مدل ترانسفورماتور
ترانسفورماتورها را می توان تقریباً برای هر کاری که یک نوع ورودی معین را برای تولید یک خروجی پردازش می کند، اعمال کرد. مثالها شامل موارد استفاده زیر است:
- ترجمه از یک زبان به زبان دیگر.
- برنامه نویسی چت ربات های جذاب تر و مفیدتر.
- جمع بندی اسناد طولانی
- ایجاد یک سند طولانی از یک درخواست کوتاه.
- ایجاد ساختارهای شیمیایی دارو بر اساس یک دستور خاص.
- تولید تصاویر از یک درخواست متنی
- ایجاد زیرنویس برای یک تصویر
- ایجاد یک اسکریپت اتوماسیون فرآیند رباتیک (RPA) از یک توضیح مختصر.
- ارائه پیشنهادات تکمیل کد بر اساس کد موجود.
پیاده سازی مدل ترانسفورماتور
پیاده سازی ترانسفورماتور از نظر اندازه، پشتیبانی از موارد استفاده جدید یا حوزه های مختلف مانند پزشکی، علمی یا برنامه های تجاری در حال بهبود است. در زیر برخی از امیدوار کننده ترین اجرای ترانسفورماتور آورده شده است:
- نمایش رمزگذار دو جهته گوگل از ترانسفورمرز یکی از اولین LLM های مبتنی بر ترانسفورماتور بود.
- GPT OpenAI از همین روش پیروی کرد و چندین بار تکرار شد، از جمله GPT-2، GPT-3، GPT-3.5، GPT-4 و ChatGPT.
- Meta’s Llama عملکردی قابل مقایسه با مدل های 10 برابر اندازه خود دارد.
- Google’s Pathways Language Model تعمیم میدهد و وظایف را در حوزههای مختلف از جمله متن، تصاویر و کنترلهای روباتیک انجام میدهد.
- Dall-E AI را باز کنید تصاویر را از توضیحات متن کوتاه ایجاد می کند.
- دانشگاه فلوریدا و GatorTron انویدیا داده های بدون ساختار را از سوابق پزشکی تجزیه و تحلیل می کنند.
- DeepMind’s Alphafold 2 نحوه جمع شدن پروتئین ها را توضیح می دهد.
- AstraZeneca و MegaMolBART انویدیا بر اساس دادههای ساختار شیمیایی، داروی جدیدی تولید میکنند.