مدلهای انتشار نویز زدایی(Denoising Diffusion Probabilistic Models (DDPM) ) که به عنوان مدلهای مولد مبتنی بر امتیاز نیز شناخته میشوند، اخیراً به عنوان یک کلاس قدرتمند از مدلهای مولد ظهور کردهاند. آنها نتایج شگفت انگیزی را در تولید تصویر با وفاداری بالا نشان می دهند که اغلب حتی از شبکه های متخاصم مولد بهتر عمل می کنند. نکته مهم، آنها علاوه بر این تنوع نمونه قوی و پوشش حالت وفادار توزیع داده های آموخته شده را ارائه می دهند.

این نشان میدهد که مدلهای انتشار حذف نویز برای یادگیری مدلهای دادههای پیچیده و متنوع مناسب هستند. مدلهای انتشار نویز زدایی، فرآیند انتشار رو به جلو را تعریف میکنند که دادهها را با ایجاد اختلال در دادههای ورودی به نویز نگاشت میکند. تولید داده با استفاده از یک فرآیند معکوس پارامتری شده و آموخته شده به دست می آید که نویز زدایی تکراری را انجام می دهد و از نویز تصادفی خالص شروع می شود (شکل بالا را ببینید). اگرچه مدل های انتشار نسبتا جدید هستند، آنها قبلاً برنامه های موفق زیادی پیدا کرده اند. به عنوان مثال، آنها در بینایی کامپیوتر برای ویرایش تصویر، سنتز تصویر قابل کنترل، معنایی و متن محور، ترجمه تصویر به تصویر، وضوح فوق العاده، تقسیم بندی تصویر، و همچنین تولید و تکمیل شکل سه بعدی استفاده شده اند.
در این آموزش، پایههای مدلهای انتشار نویز زدایی، از جمله فرمولبندی مرحلهای گسسته و همچنین توصیف مبتنی بر معادلات دیفرانسیل آنها را خلاصه میکنیم. ما همچنین جزئیات پیادهسازی عملی مربوط به پزشکان را مورد بحث قرار میدهیم و اتصالات به سایر مدلهای مولد موجود را برجسته میکنیم، در نتیجه مدلهای انتشار نویز زدایی را در یک زمینه گستردهتر قرار میدهیم. علاوه بر این، افزونههای فنی اخیر و روشهای پیشرفته برای نمونهبرداری سریع، تولید مشروط و فراتر از آن را مرور میکنیم. نمونه برداری آهسته نقطه ضعف اصلی مدل های انتشار نویز زدایی بوده است. با این حال، بسیاری از تکنیک های امیدوار کننده برای غلبه بر این چالش پدیدار شده است. مدلهای انتشار اخیراً حذف نویز نیز پیشرفت شگفتانگیزی در وظایف تولید شرطی با وضوح بالا داشتهاند، به عنوان مثال، تولید متن به تصویر، و ما چندین تکنیک پیشرفته کلیدی را برای دستیابی به آن مورد بحث قرار می دهیم. برای نشان دادن اینکه چگونه میتوان مدلهای انتشار نویز زدایی را برای موارد استفاده از بینایی تنظیم کرد، ما همچنین برنامههای موفق در بینایی کامپیوتر را بررسی میکنیم.
با توجه به نقاط قوت منحصر به فرد مدل های انتشار، این است که به طور همزمان کیفیت تولید بالا و همچنین پوشش و تنوع حالت، و همچنین کارهای اخیر در مورد نمونه برداری سریع و تولید مشروط را ارائه می دهد، پیش بینی می کنیم که آنها به طور گسترده در بینایی کامپیوتر و گرافیک مورد استفاده قرار گیرند. متأسفانه، مدلهای انتشار بر مفاهیم نسبتاً فنی متکی هستند، و در نتیجه در بسیاری از حوزههای کاربردی، پتانسیل واقعی این مدلها هنوز آشکار نشده است، زیرا جامعه کار بر روی آنها هنوز نسبتاً کوچک است. هدف اصلی این آموزش این است که با ارائه یک دوره کوتاه مقدماتی، مدلهای انتشار را برای مخاطبان بینایی کامپیوتری در دسترس قرار دهد.این آموزش مبتنی بر مفاهیم ساده در یادگیری مولد است و دانش اساسی را در اختیار محققان و متخصصان علاقهمند قرار میدهد تا در این زمینه هیجانانگیز شروع به کار کنند.
مدلهای احتمالی انتشار یک حوزه جدید و هیجانانگیز از تحقیقات هستند که نویدبخش تولید تصویر هستند. در نگاهی به گذشته، مدلهای مولد مبتنی بر انتشار برای اولین بار در سال 2015 معرفی شدند و در سال 2020 زمانی که هو و همکارانش رایج شدند. مقاله “مدل های احتمالی انتشار دیونیز” (DDPMs) را منتشر کرد. DDPM ها مسئول عملی ساختن مدل های انتشار هستند. در این مقاله، مفاهیم و تکنیکهای کلیدی پشت DDPMها را برجسته میکنیم و DDPMها را از ابتدا بر روی مجموعه داده «گلها» برای تولید تصویر بدون قید و شرط آموزش میدهیم.
در DDPM ها، نویسندگان روش های آموزش فرمول بندی و مدل را تغییر دادند که به بهبود و دستیابی به “وفاداری تصویر” رقیب GAN ها کمک کرد و اعتبار این الگوریتم های مولد جدید را ایجاد کرد.
بهترین رویکرد برای درک کامل «مدلهای احتمالی انتشار دیونیز» ، بررسی هر دو نظریه (+ مقداری ریاضی) و کد زیربنایی است. با در نظر گرفتن این موضوع، بیایید مسیر یادگیری را بررسی کنیم که در آن:
- ابتدا توضیح خواهیم داد که مدل های مولد چیست و چرا به آنها نیاز است.
- ما از دیدگاه نظری، رویکرد مورد استفاده در مدلهای مولد مبتنی بر انتشار را مورد بحث قرار خواهیم داد.
- ما تمام ریاضیات لازم برای درک مدلهای احتمالی انتشار دیودیز را بررسی میکنیم.
- در نهایت، آموزش و استنتاج مورد استفاده در DDPM ها برای تولید تصویر را مورد بحث قرار می دهیم و آن را از ابتدا در PyTorch کدگذاری می کنیم.
- مزایا : قابلیت جابجایی و انعطاف پذیری دو هدف متناقض در مدل سازی مولد هستند. مدلهای Tractable را میتوان بهصورت تحلیلی ارزیابی کرد و دادههای ارزانقیمتی را متناسب کرد (مثلاً از طریق گاوسی یا لاپلاس)، اما آنها نمیتوانند به راحتی ساختار را در مجموعه دادههای غنی توصیف کنند. مدلهای انعطافپذیر میتوانند ساختارهای دلخواه را در دادهها جای دهند، اما ارزیابی، آموزش یا نمونهبرداری از این مدلها معمولاً گران است. مدل های انتشار هم از نظر تحلیلی قابل کشش و هم انعطاف پذیر هستند
- معایب : مدلهای انتشار برای تولید نمونهها به زنجیره طولانی مارکوف از مراحل انتشار متکی هستند، بنابراین میتواند از نظر زمان و محاسبه بسیار گران باشد. روشهای جدیدی برای سریعتر کردن فرآیند پیشنهاد شدهاند، اما نمونهبرداری هنوز کندتر از GAN است.
نیاز به مدل های مولد
کار مدلهای تولیدی مبتنی بر تصویر ، تولید تصاویر جدیدی است که مشابه، به عبارت دیگر، «نماینده» مجموعه اصلی تصاویر ما هستند.
ما نیاز به ایجاد و آموزش مدلهای مولد داریم، زیرا مجموعهای از تمام تصاویر ممکن که میتوانند مثلاً با تصاویر (256x256x3) نمایش داده شوند، بسیار زیاد است. یک تصویر باید ترکیبات پیکسلی مناسبی برای نمایش چیزی معنادار (چیزی که ما می توانیم درک کنیم) داشته باشد.

به عنوان مثال، برای اینکه تصویر بالا نشان دهنده یک “آفتابگردان” باشد، پیکسل های تصویر باید در پیکربندی مناسب باشند (آنها باید مقادیر مناسبی داشته باشند). و فضایی که چنین تصاویری وجود دارد فقط کسری از کل مجموعه تصاویر است که می تواند با یک فضای تصویر (256x256x3) نمایش داده شود. حال، اگر میدانستیم چگونه یک نقطه را از این زیرفضا به دست آوریم/نمونهبرداری کنیم، نیازی به ساخت «مدلهای مولد»
نداشتیم . با این حال، در این مقطع زمانی، ما این کار را نمی کنیم. 😓
تابع توزیع احتمال یا بهطور دقیقتر، تابع چگالی احتمال (PDF) که این زیرفضای (داده) را میگیرد/مدلسازی میکند، ناشناخته باقی میماند و به احتمال زیاد آنقدر پیچیده است که معنا ندارد.
به همین دلیل است که ما به «مدلهای تولیدی» نیاز داریم – برای کشف تابع احتمال اساسی که دادههای ما برآورده میکنند.
PS: یک PDF یک “تابع احتمال” است که چگالی (احتمال) یک متغیر تصادفی پیوسته را نشان می دهد – که در این مورد به معنای تابعی است که احتمال وجود یک تصویر بین محدوده خاصی از مقادیر تعریف شده توسط پارامترهای تابع را نشان می دهد.
PPS: هر PDF دارای مجموعه ای از پارامترها است که شکل و احتمالات توزیع را تعیین می کند. شکل توزیع با تغییر مقادیر پارامتر تغییر می کند. به عنوان مثال، در مورد توزیع نرمال، ما میانگین μ (mu) و واریانس σ2 (سیگما) داریم که نقطه مرکزی توزیع و گسترش را کنترل می کنند.

منبع: https://magic-with-latents.github.io/latent/posts/ddpms/part2/
مدل های احتمالی انتشار چیست؟
در پست قبلی ما، ” مقدمه ای بر مدل های انتشار برای تولید تصویر “، ما در مورد ریاضیات پشت این مدل ها صحبت نکردیم. ما فقط یک نمای کلی مفهومی از نحوه عملکرد مدلهای انتشار ارائه کردیم و بر مدلهای مختلف شناخته شده و کاربردهای آنها تمرکز کردیم. در این مقاله، ما به شدت بر قسمت اول تمرکز خواهیم کرد.
در این بخش، مدلهای مولد مبتنی بر انتشار را از منظر منطقی و نظری توضیح خواهیم داد. در مرحله بعد، تمام ریاضیات مورد نیاز برای درک و اجرای مدلهای احتمالی انتشار نویز زدایی را از ابتدا بررسی میکنیم.
مدلهای انتشار دستهای از مدلهای مولد هستند که از ایدهای در فیزیک آماری غیرتعادلی الهام گرفته شدهاند که بیان میکند:
“ما می توانیم به تدریج یک توزیع را با استفاده از زنجیره مارکوف به توزیع دیگر تبدیل کنیم.”
– یادگیری بدون نظارت عمیق با استفاده از ترمودینامیک غیرتعادلی، 2015
مدلهای مولد انتشار از دو فرآیند متضاد یعنی فرآیند انتشار رو به جلو و معکوس تشکیل شدهاند .
فرآیند انتشار به جلو :
“از بین بردن آسان است اما ساختن آن سخت است”
– پرل اس باک
- در فرآیند “انتشار رو به جلو”، ما به آرامی و به طور مکرر نویز را به تصاویر موجود در مجموعه آموزشی خود اضافه می کنیم (فاسد می کنیم) به طوری که آنها از فضای فرعی موجود خود “حرکت می کنند یا دور می شوند”.
- کاری که ما در اینجا انجام می دهیم، تبدیل توزیع ناشناخته و پیچیده ای است که مجموعه آموزشی ما به آن تعلق دارد، به توزیعی که نمونه برداری از یک نقطه (داده) و درک آن برای ما آسان باشد.
- در پایان فرآیند رو به جلو، تصاویر کاملاً غیرقابل تشخیص می شوند . توزیع داده های پیچیده به طور کامل به یک توزیع ساده (انتخابی) تبدیل می شود. هر تصویر به فضایی خارج از زیرفضای داده نگاشت می شود.

فرآیند انتشار معکوس :
با تجزیه فرآیند تشکیل تصویر به یک برنامه متوالی از رمزگذارهای خودکار حذف نویز، مدلهای انتشار (DMs) به نتایج سنتز پیشرفتهای روی دادههای تصویر و فراتر از آن دست مییابند.
انتشار پایدار، 2022

- در «فرایند انتشار معکوس»، ایده این است که فرآیند انتشار رو به جلو را معکوس کنیم.
- ما به آهستگی و به طور مکرر سعی می کنیم تا خرابی ایجاد شده روی تصاویر را در روند رو به جلو معکوس کنیم.
- فرآیند معکوس از جایی شروع می شود که روند رو به جلو به پایان می رسد.
- مزیت شروع از یک فضای ساده این است که ما می دانیم چگونه یک نقطه را از این توزیع ساده بدست آوریم/نمونه برداری کنیم (آن را به عنوان هر نقطه ای خارج از زیرفضای داده در نظر بگیرید).
- و هدف ما در اینجا این است که بفهمیم چگونه به زیرفضای داده بازگردیم.
- با این حال، مشکل این است که میتوانیم مسیرهای بینهایتی را طی کنیم که از یک نقطه در این فضای «ساده» شروع میشوند، اما تنها کسری از آنها ما را به زیرفضای «داده» میبرند.
- در مدلهای احتمالی انتشار، این کار با مراجعه به گامهای تکراری کوچکی که در طول فرآیند انتشار به جلو انجام میشود، انجام میشود.
- PDF که تصاویر خراب شده را در روند رو به جلو برآورده می کند، در هر مرحله کمی متفاوت است.
- از این رو، در فرآیند معکوس، ما از یک مدل یادگیری عمیق در هر مرحله برای پیشبینی پارامترهای PDF فرآیند رو به جلو استفاده میکنیم.
- و هنگامی که مدل را آموزش دادیم، میتوانیم از هر نقطهای در فضای ساده شروع کنیم و از مدل برای برداشتن مراحل تکراری استفاده کنیم تا ما را به زیرفضای داده برگردانیم.
- در انتشار معکوس، ما به طور مکرر “نویز زدایی” را در مراحل کوچک انجام می دهیم، که از یک تصویر نویز شروع می شود.
- این رویکرد برای آموزش و تولید نمونههای جدید بسیار پایدارتر از GANها و بهتر از رویکردهای قبلی مانند رمزگذارهای خودکار متغیر (VAE) و عادیسازی جریانها است.

از زمان معرفی آنها در سال 2020، DDPM ها پایه و اساس سیستم های تولید تصویر پیشرفته از جمله DALL-E 2، Imagen، Stable Diffusion و Midjourney بوده اند.
امروزه با وجود تعداد زیادی ابزار تولید هنر هوش مصنوعی، یافتن ابزار مناسب برای یک مورد خاص دشوار است. در مقاله اخیر خود، همه ابزارهای مختلف تولید هنر هوش مصنوعی را بررسی کردیم تا بتوانید انتخابی آگاهانه برای تولید بهترین هنر داشته باشید.
تا کنون، من در مورد سه نوع مدل مولد، GAN ، VAE و مدل های مبتنی بر جریان نوشته ام . آنها موفقیت زیادی در تولید نمونه های با کیفیت بالا از خود نشان داده اند، اما هر کدام محدودیت های خاص خود را دارند. مدلهای GAN برای آموزش بالقوه ناپایدار و تنوع کمتر در تولید به دلیل ماهیت آموزشی متخاصم شناخته شدهاند. VAE متکی به ضرر جایگزین است. مدل های جریان باید از معماری های تخصصی برای ساخت تبدیل برگشت پذیر استفاده کنند.
مدل های انتشار از ترمودینامیک غیرتعادلی الهام گرفته شده اند. آنها یک زنجیره مارکوف از مراحل انتشار تعریف می کنند تا به آرامی نویز تصادفی را به داده ها اضافه کنند و سپس یاد بگیرند که روند انتشار را معکوس کنند تا نمونه های داده دلخواه را از نویز بسازند. برخلاف مدلهای VAE یا جریان، مدلهای انتشار با یک روش ثابت آموخته میشوند و متغیر پنهان ابعاد بالایی دارد (همانند دادههای اصلی).
 شکل 1. مروری بر انواع مختلف مدل های مولد.
شکل 1. مروری بر انواع مختلف مدل های مولد.
جزئیات ریاضی Itsy-Bitsy پشت مدلهای احتمالی انتشار نویز زدایی
از آنجایی که انگیزه پشت این پست «ایجاد و آموزش مدلهای احتمالی انتشار نویز زدایی از ابتدا» است، ممکن است مجبور باشیم نه همه، بلکه برخی از جادوهای ریاضی پشت آنها را معرفی کنیم.
در این بخش، تمام ریاضیات مورد نیاز را پوشش میدهیم و در عین حال مطمئن میشویم که رعایت آن نیز آسان است.
شروع کنیم…

در فلش ها دو عبارت ذکر شده است:
 –
–
- این اصطلاح به عنوان هسته انتشار رو به جلو (FDK) نیز شناخته می شود .
- PDF یک تصویر را در مرحله زمانی t در فرآیند انتشار رو به جلو x t تصویر داده شده x t-1 تعریف می کند .
- این “تابع انتقال” را نشان می دهد که در هر مرحله در فرآیند انتشار به جلو اعمال می شود .
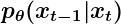 –
–
- مشابه فرآیند رو به جلو، به عنوان هسته انتشار معکوس (RDK) شناخته می شود.
- این مخفف PDF x t-1 است که x t را با پارامتر 𝜭 داده شده است . منظور از 𝜭 این است که پارامترهای توزیع فرآیند معکوس با استفاده از یک شبکه عصبی آموخته می شوند.
- این “تابع انتقال” است که در هر مرحله در فرآیند انتشار معکوس اعمال می شود .
جزئیات ریاضی فرآیند انتشار رو به جلو
توزیع q در فرآیند انتشار به جلو به صورت زنجیره مارکوف تعریف می شود که توسط:

- ما با گرفتن یک تصویر از مجموعه داده خود شروع می کنیم: x 0 . از نظر ریاضی به عنوان نمونهبرداری از یک نقطه داده از توزیع داده اصلی (اما ناشناخته) بیان میشود: x 0 ~ q (x 0 ) .
- PDF فرآیند رو به جلو محصول توزیع فردی است که از مرحله زمانی 1 → T شروع می شود .
- فرآیند انتشار به جلو ثابت و شناخته شده است.
- تمام تصاویر نویزدار متوسط که از مرحله زمانی 1 تا T شروع می شوند ، “مخفف” نیز نامیده می شوند. ابعاد نهفته ها همانند تصویر اصلی است.
- PDF مورد استفاده برای تعریف FDK یک ” توزیع عادی/گاوسی” است (معادل 2).
- در هر مرحله زمانی t، پارامترهایی که توزیع تصویر x t را تعریف می کنند به صورت زیر تنظیم می شوند:
- منظور داشتن:
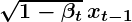
- کوواریانس:
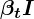
- منظور داشتن:
- اصطلاح 𝝱 (بتا) به عنوان “نرخ انتشار” شناخته می شود و با استفاده از “زمانبندی واریانس” از قبل محاسبه می شود. اصطلاح I یک ماتریس هویت است. بنابراین، توزیع در هر مرحله زمانی را گاوسی ایزوتروپیک می نامند.
- تصویر اصلی در هر مرحله زمانی با افزودن مقدار کمی نویز گاوسی ( ɛ ) خراب می شود. میزان نویز اضافه شده توسط زمانبندی تنظیم می شود.
- با انتخاب گامهای زمانی به اندازه کافی بزرگ و تعریف یک زمانبندی خوب از 𝝱 t ، کاربرد مکرر FDK به تدریج توزیع دادهها را تقریباً به یک توزیع گاوسی همسانگرد تبدیل میکند.

چگونه تصویر x t را از x t-1 دریافت کنیم و نویز چگونه در هر مرحله زمانی اضافه می شود؟
این را می توان به راحتی با استفاده از ترفند پارامترسازی مجدد در رمزگذارهای خودکار متغیر فهمید .
با مراجعه به معادله دوم ، میتوانیم به راحتی تصویر x t را از یک توزیع نرمال نمونهبرداری کنیم:

- در اینجا، epsilon ɛ عبارت “نویز” است که به طور تصادفی از توزیع استاندارد گاوسی نمونه برداری می شود و ابتدا مقیاس بندی می شود و سپس اضافه می شود (مقیاس شده) x (t-1) .
- به این ترتیب، با شروع از x 0 ، تصویر اصلی به طور مکرر از t=1…T خراب می شود.
در عمل، نویسندگان DDPM از « زمانبندی واریانس خطی» استفاده میکنند و 𝝱 در محدوده تعریف میکنند [0.0001, 0.02] و کل گامهای زمانی را تنظیم میکنند.T = 1000
مدلهای انتشار ، دادهها را با هر مرحله فرآیند رو به جلو (با یک
فاکتور) به طوری که هنگام اضافه کردن نویز واریانس رشد نمی کند. ”
– مدلهای احتمالی انتشار نویز، 2020

در اینجا یک مشکل وجود دارد که منجر به یک روند رو به جلو ناکارآمد می شود 🐢.
هر زمان که در مرحله زمانی t به نمونه نهفته x نیاز داشته باشیم، باید مراحل t-1 را در زنجیره مارکوف انجام دهیم.

برای رفع این مشکل، نویسندگان DDPM هسته را مجدداً فرموله کردند تا مستقیماً از مرحله زمانی 0 (یعنی از تصویر اصلی) به مرحله زمانی t در فرآیند برود.

برای انجام این کار، دو اصطلاح اضافی تعریف شده است:

جایی که eqn. (5) محصول تجمعی 𝛂 از 1 تا t است.
و سپس، با استفاده از ویژگی جمع توزیع گاوسی، با جایگزینی 𝝱 ‘swith ‘ sand . فرآیند انتشار رو به جلو را می توان بر حسب 𝛂 بازنویسی کرد :

🚀 با استفاده از فرمول بالا، می توانیم در هر مرحله زمانی دلخواه t در زنجیره مارکوف نمونه برداری کنیم.
این همه برای فرآیند انتشار رو به جلو است.
جزئیات ریاضی فرآیند انتشار معکوس

در فرآیند انتشار معکوس، وظیفه یادگیری معکوس زمان محدود (در گامهای T) فرآیند انتشار به جلو است.
این اساساً به این معنی است که ما باید فرآیند فوروارد را “لغو” کنیم، یعنی نویز اضافه شده در فرآیند فوروارد را به طور مکرر حذف کنیم. با استفاده از مدل شبکه عصبی انجام می شود.
در فرآیند رو به جلو، تابع انتقال q با استفاده از گاوسی تعریف شد، بنابراین چه تابعی باید برای فرآیند معکوس استفاده شود ؟ شبکه عصبی چه چیزی را باید یاد بگیرد؟ p
- در سال 1949، W. Feller نشان داد که برای توزیعهای گاوسی (و دوجملهای)، وارونگی فرآیند انتشار همان شکل عملکردی فرآیند رو به جلو را دارد.
- این بدان معنی است که مشابه FDK که به عنوان یک توزیع نرمال تعریف می شود، می توانیم از همان فرم عملکردی (یک توزیع گاوسی) برای تعریف هسته انتشار معکوس استفاده کنیم.
- فرآیند معکوس نیز یک زنجیره مارکوف است که در آن یک شبکه عصبی پارامترهای هسته انتشار معکوس را در هر مرحله زمانی پیشبینی میکند.
- در طول آموزش، برآوردهای آموخته شده (پارامترها) باید در هر مرحله زمانی نزدیک به پارامترهای FDK پسین باشد. در بخش بعدی بیشتر در مورد پسین FDK صحبت خواهیم کرد .
- ما این را می خواهیم زیرا اگر مسیر رو به جلو را به صورت معکوس دنبال کنیم، ممکن است به توزیع داده اصلی برگردیم.
- با انجام این کار، ما همچنین یاد میگیریم که چگونه نمونههای جدیدی تولید کنیم که دقیقاً با توزیع دادههای زیربنایی مطابقت داشته باشند، با شروع از نویز گاوسی خالص (ما در طول استنتاج به فرآیند رو به جلو دسترسی نداریم).

- زنجیره مارکوف برای انتشار معکوس از جایی شروع میشود که فرآیند رو به جلو به پایان میرسد، یعنی در مرحله زمانی T ، جایی که توزیع دادهها به (تقریباً یک) توزیع گاوسی همسانگرد تبدیل شده است.

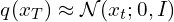
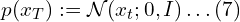
- PDF فرآیند انتشار معکوس یک “انتگرال” در تمام مسیرهای ممکنی است که می توانیم برای رسیدن به نمونه داده (در همان توزیع اصلی) از نویز خالص x T استفاده کنیم .



هدف آموزشی و تابع تلفات مورد استفاده در مدلهای احتمالی انتشار نویز زدایی
هدف آموزشی مدلهای مولد مبتنی بر انتشار عبارت است از “به حداکثر رساندن احتمال ورود به سیستم نمونه تولید شده (در پایان فرآیند معکوس) ( x ) متعلق به توزیع داده اصلی.”
ما توابع انتقال را در مدلهای انتشار به صورت «گاوسی» تعریف کردهایم. برای به حداکثر رساندن احتمال ورود به سیستم یک توزیع گاوسی، سعی کنید پارامترهای توزیع (𝞵 ، 𝝈 2 ) را به گونه ای بیابید که “احتمال” داده (تولید شده) متعلق به همان توزیع داده را به حداکثر برساند. داده های اصلی
برای آموزش شبکه عصبی خود، تابع ضرر (L) را به عنوان منفی تابع هدف تعریف می کنیم. بنابراین مقدار زیاد برای p _ _

به نظر می رسد، این غیرقابل حل است زیرا ما باید در یک فضای ابعادی (پیکسلی) بسیار بالا برای مقادیر پیوسته در گام های زمانی T یکپارچه کنیم .
در عوض، نویسندگان از VAE ها الهام می گیرند و هدف آموزشی را با استفاده از یک کران پایین متغیر (VLB)، که به عنوان «کران پایین شواهد» (ELBO) نیز شناخته می شود، دوباره فرموله می کنند ، که این معادله ترسناک به نظر می رسد.


پس از کمی سادهسازی، نویسندگان DDPM به این اصطلاح نهایی L vlb – Variational Lower Bound loss میرسند:

میتوانیم عبارت ضرر L vlb بالا را به صورت زیر به گامهای زمانی جداگانه تقسیم کنیم:

ممکن است متوجه شوید که این تابع ضرر بسیار زیاد است! اما نویسندگان DDPM آن را با نادیده گرفتن برخی از اصطلاحات در تابع ضرر ساده شده خود ساده تر می کنند.
اصطلاحات نادیده گرفته شده عبارتند از:
- L 0 – نویسندگان بدون این نتایج بهتری گرفتند.
- L T – این “واگرایی KL” بین توزیع نهفته نهایی در فرآیند رو به جلو و اولین نهفته در فرآیند معکوس است. با این حال، هیچ پارامتر شبکه عصبی در اینجا دخیل نیست، بنابراین ما نمیتوانیم کاری در مورد آن انجام دهیم جز اینکه یک زمانبندی واریانس خوب تعریف کنیم و از گامهای زمانی بزرگ استفاده کنیم به طوری که هر دو یک توزیع گاوسی ایزوتروپیک را نشان دهند.
بنابراین L t-1 تنها عبارت از دست دادن باقی مانده است که یک واگرایی KL بین “خلفی” فرآیند رو به جلو (مشروط بر xt و نمونه اولیه x 0 ) و فرآیند انتشار معکوس پارامتر شده است . هر دو عبارت توزیع گاوسی نیز هستند.

اصطلاح q(xt -1 |xt ، x 0 ) به عنوان “توزیع پسین فرآیند پیشرو” نامیده می شود .
کار مدل یادگیری عمیق ما در طول آموزش این است که پارامترهای این (گاوسی) پسین را تقریب / تخمین بزند به طوری که واگرایی KL تا حد امکان حداقل باشد.

پارامترهای توزیع پسین به شرح زیر است:

برای سادهتر کردن کار مدل، نویسندگان تصمیم گرفتند واریانس را روی یک ثابت 𝝱 t ثابت کنند .
حال، مدل فقط باید یاد بگیرد که معادله فوق را پیش بینی کند. و هسته انتشار معکوس به شکل زیر تغییر می کند:

همانطور که واریانس را ثابت نگه داشته ایم، به حداقل رساندن واگرایی KL به سادگی به حداقل رساندن تفاوت (یا فاصله) بین میانگین (𝞵) دو توزیع گاوسی q و p ( برای مثال تفاوت بین میانگین توزیع ها در تصویر سمت چپ ) است. می توان به صورت زیر انجام داد:

اکنون، سه رویکرد وجود دارد که می توانیم در اینجا در نظر بگیریم:
- به طور مستقیم x 0 را پیش بینی کنید و پیدا کنید
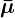 استفاده از آن در عملکرد خلفی .
استفاده از آن در عملکرد خلفی . - کل را پیش بینی کنیدمدت، اصطلاح.
- نویز را در هر مرحله پیش بینی کنید. این کار با نوشتن x 0 در این انجام می شودبر حسب x t با استفاده از ترفند پارامترسازی مجدد.
با استفاده از گزینه سوم و پس از کمی ساده سازی،را می توان به صورت زیر بیان کرد:

به طور مشابه، فرمول برای 𝞵 𝞱 (x t , t) به صورت زیر تنظیم شده است:
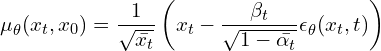
در زمان آموزش و استنتاج، ما s ، ❛ و x t را می شناسیم . بنابراین مدل ما فقط نیاز به پیش بینی نویز در هر مرحله دارد. تابع کاهش ساده شده (بعد از نادیده گرفتن برخی از اصطلاحات وزن دهی) مورد استفاده در مدل های احتمالی انتشار نویز به شرح زیر است:

که در اصل این است:

این تابع تلفات نهایی است که ما برای آموزش DDPM ها استفاده می کنیم، که فقط یک “میانگین مربع خطا” بین نویز اضافه شده در فرآیند جلو و نویز پیش بینی شده توسط مدل است. این تأثیرگذارترین سهم مقاله مدلهای احتمالی انتشار نویز است.
این فوقالعاده است زیرا، با شروع از آن اصطلاحات ترسناک ELBO، ما به سادهترین عملکرد از دست دادن در کل دامنه یادگیری ماشینی دست یافتیم.
شبکههای متخاصم مولد (GAN) که در سال 2014 توسط Ian Goodfellow معرفی شد ، هنجار تولید نمونههای تصویر بودند.
تغییرات زیادی از GAN های اصلی ایجاد شد، مانند:
- Conditional GAN (cGAN) : کنترل کلاس/رده تصاویر تولید شده.
- Deep Convolutional GAN (DCGAN) : معماری به طور قابل توجهی کیفیت GAN ها را با استفاده از لایه های کانولوشن بهبود می بخشد.
- ترجمه تصویر به تصویر با Pix2Pix : تبدیل تصاویر از یک دامنه به دامنه دیگر با یادگیری نقشه برداری بین ورودی و خروجی.
نوشتن DDPM از ابتدا در PyTorch
از این بخش، تمام اجزای ضروری مورد نیاز برای آموزش مدلهای احتمالی انتشار نویز را از ابتدا در PyTorch کدنویسی میکنیم. به جای Colab، ما از هسته های Kaggle استفاده کردیم زیرا GPU های بهتری نسبت به نسخه رایگان Colab و زمان های آموزشی طولانی تری ارائه می دهد (که برای مدل های انتشار بسیار مهم است).
توجه: کد برای توابع کمکی که به طور منظم استفاده می شود به پست اضافه نمی شود.
💡 شما می توانید با عضویت در پست وبلاگ به کل پایگاه کد این پست و سایر پست های ما دسترسی داشته باشید و ما لینک دانلود لینک را برای شما ارسال می کنیم.
دانلود کد برای پیگیری آسان این آموزش، لطفا با کلیک بر روی دکمه زیر کد را دانلود کنید. رایگان است!
اول از همه، کلاسهای پیکربندی را تعریف میکنیم که ابرپارامترها را برای بارگذاری مجموعه داده، ایجاد فهرستهای فهرست و آموزش مدل نگه میدارند.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from dataclasses import dataclass@dataclassclass BaseConfig: DEVICE = get_default_device() DATASET = "Flowers" # "MNIST", "Cifar-10", "Flowers" # For logging inferece images and saving checkpoints. root_log_dir = os.path.join("Logs_Checkpoints", "Inference") root_checkpoint_dir = os.path.join("Logs_Checkpoints", "checkpoints") # Current log and checkpoint directory. log_dir = "version_0" checkpoint_dir = "version_0"@dataclassclass TrainingConfig: TIMESTEPS = 1000 # Define number of diffusion timesteps IMG_SHAPE = (1, 32, 32) if BaseConfig.DATASET == "MNIST" else (3, 32, 32) NUM_EPOCHS = 800 BATCH_SIZE = 32 LR = 2e-4 NUM_WORKERS = 2 |
ایجاد شیء کلاس مجموعه داده PyTorch
این مقاله از مجموعه داده “Flowers” استفاده می کند که می تواند از Kaggle بارگیری شود یا به سرعت در محیط Kaggle kernel بارگیری شود. اما همانطور که ممکن است متوجه شده باشید، در BaseConfigکلاس، گزینه بارگیری مجموعه داده های MNIST، Cifar-10 و Cifar-100 را نیز ارائه کرده ایم. شما می توانید هر کدام را که ترجیح می دهید انتخاب کنید.
مجموعه داده گل ها را می توانید از اینجا دانلود کنید: شناسایی گل ها | کاگل
هنگام استفاده از کرنل های Kaggle، به سادگی روی مولفه «افزودن داده» کلیک کنید و مجموعه داده را انتخاب کنید.
در اینجا، ما دو تابع ایجاد می کنیم:
get_dataset(...): شی کلاس مجموعه داده را که به Dataloader ارسال می شود برمی گرداند. سه تبدیل پیش پردازش و یک افزایش برای هر تصویر در مجموعه داده اعمال می شود.- پیش پردازش:
- تبدیل مقادیر پیکسل از محدوده
[0, 255] → [0.0, 1.0] - اندازه تصاویر را به شکل تغییر دهید
(32x32). - مقادیر پیکسل را از محدوده تغییر دهید
[0.0, 1.0] → [-1.0, 1.0]. این کار توسط نویسندگان DDPM انجام می شود به طوری که تصویر ورودی تقریباً همان محدوده مقادیر یک گاوسی استاندارد را داشته باشد.
- تبدیل مقادیر پیکسل از محدوده
- افزایش:
- A
random horizontal flip، همانطور که در اجرای اصلی استفاده شده است. در صورتی که از مجموعه داده MNIST استفاده می کنید، حتماً در این خط نظر دهید.
- A
- پیش پردازش:
inverse_transforms(...): این تابع برای معکوس کردن تبدیل های اعمال شده در مرحله بارگذاری و برگرداندن تصویر به محدوده استفاده می شود[0.0, 255.0].
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import torchvisionimport torchvision.transforms as TFimport torchvision.datasets as datasetsfrom torch.utils.data import Dataset, DataLoaderdef get_dataset(dataset_name='MNIST'): transforms = torchvision.transforms.Compose( [ torchvision.transforms.ToTensor(), torchvision.transforms.Resize((32, 32), interpolation=torchvision.transforms.InterpolationMode.BICUBIC, antialias=True), torchvision.transforms.RandomHorizontalFlip(),# torchvision.transforms.Normalize(MEAN, STD), torchvision.transforms.Lambda(lambda t: (t * 2) - 1) # Scale between [-1, 1] ] ) if dataset_name.upper() == "MNIST": dataset = datasets.MNIST(root="data", train=True, download=True, transform=transforms) elif dataset_name == "Cifar-10": dataset = datasets.CIFAR10(root="data", train=True, download=True, transform=transforms) elif dataset_name == "Cifar-100": dataset = datasets.CIFAR10(root="data", train=True, download=True, transform=transforms) elif dataset_name == "Flowers": dataset = datasets.ImageFolder(root="/kaggle/input/flowers-recognition/flowers", transform=transforms) return datasetdef inverse_transform(tensors): """Convert tensors from [-1., 1.] to [0., 255.]""" return ((tensors.clamp(-1, 1) + 1.0) / 2.0) * 255.0 |
ایجاد شی کلاس PyTorch Dataloader
در مرحله بعد، تابعی را تعریف می کنیم get_dataloader(...)که یک Dataloaderشی را برای مجموعه داده انتخابی برمی گرداند.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def get_dataloader(dataset_name='MNIST', batch_size=32, pin_memory=False, shuffle=True, num_workers=0, device="cpu" ): dataset = get_dataset(dataset_name=dataset_name) dataloader = DataLoader(dataset, batch_size=batch_size, pin_memory=pin_memory, num_workers=num_workers, shuffle=shuffle ) # Used for moving batch of data to the user-specified machine: cpu or gpu device_dataloader = DeviceDataLoader(dataloader, device) return device_dataloader |
تجسم مجموعه داده
ابتدا، با فراخوانی تابع، شی “dataloader” را ایجاد می کنیم get_dataloader(...).
|
1
2
3
4
5
|
loader = get_dataloader( dataset_name=BaseConfig.DATASET, batch_size=128, device=”cpu”,) |
سپس می توانیم به سادگی از تابع Torchvision make_grid(...)برای ترسیم شبکه ای از تصاویر گل استفاده کنیم.
|
1
2
3
4
5
6
7
8
9
10
|
from torchvision.utils import make_gridplt.figure(figsize=(10, 4), facecolor='white')for b_image, _ in loader: b_image = inverse_transform(b_image) grid_img = make_grid(b_image / 255.0, nrow=16, padding=True, pad_value=1) plt.imshow(grid_img.permute(1, 2, 0)) plt.axis("off") break |

معماری مدل مورد استفاده در DDPM ها
در DDPM ها، نویسندگان از یک شبکه عصبی عمیق UNet شکل استفاده می کنند که به عنوان ورودی می گیرد:
- تصویر ورودی در هر مرحله از فرآیند معکوس.
- مرحله زمانی تصویر ورودی
از معماری معمول UNet، نویسندگان کانولوشن دوگانه اصلی را در هر سطح با “بلوک های باقیمانده” که در مدل های ResNet استفاده می شود جایگزین کردند.
معماری شامل 5 جزء است:
- بلوک های رمزگذار
- بلوک های گلوگاه
- بلوک های رسیور
- ماژول های توجه به خود
- تعبیه های زمانی سینوسی
جزئیات معماری:
- چهار سطح در مسیر رمزگذار و رمزگشا وجود دارد که بلوک های گلوگاه بین آنها وجود دارد.
- هر مرحله رمزگذار شامل دو بلوک باقیمانده با نمونه برداری کانولوشنی به جز آخرین سطح است.
- هر مرحله رمزگشای مربوطه شامل سه بلوک باقیمانده است و از 2 برابر نزدیکترین همسایگان با کانولوشن برای نمونهبرداری از ورودی از سطح قبلی استفاده میکند.
- هر مرحله در مسیر رمزگذار با کمک اتصالات پرش به مسیر رمزگشا متصل می شود.
- این مدل از ماژولهای «توجه به خود» با وضوح نقشه واحد استفاده میکند.
- هر بلوک باقیمانده در مدل، ورودیهای لایه قبلی (و بقیه در مسیر رمزگشا) و جاسازی مرحله زمانی فعلی را دریافت میکند. تعبیه گام زمانی مدل را از موقعیت فعلی ورودی در زنجیره مارکوف مطلع می کند.

در این مقاله بر روی اندازه تصویر (32×32) کار می کنیم . فقط دو تغییر جزئی بین مدل ما و مدل اصلی استفاده شده در مقاله وجود دارد.
- ما
64از کانال های پایه به جای استفاده می کنیم128. - چهار سطح در مسیر رمزگذار و رمزگشا وجود دارد. اندازه نقشه های ویژگی در هر سطح به شرح زیر است:
32 →16 → 8 → 8. ما توجه خود را در اندازههای نقشه ویژگی هر دو(16x16)و(8x8)بر خلاف نسخه اصلی اعمال میکنیم، جایی که آنها فقط یک بار در اندازه نقشه ویژگی اعمال میشوند(16x16).
لطفاً توجه داشته باشید که ما کد مدل را اضافه نمی کنیم زیرا کد UNet + این تغییرات بسیار آسان است، بلکه به دلیل همه اجزای مختلف است. برای اضافه شدن به پست خیلی بزرگ می شود .
کلاس انتشار
در این قسمت کلاسی به نام SimpleDiffusion ایجاد می کنیم. این کلاس شامل:
- ثابت های زمانبند مورد نیاز برای انجام فرآیند انتشار رو به جلو و معکوس.
- روشی برای تعریف زمانبندی واریانس خطی مورد استفاده در DDPM.
- روشی که یک مرحله را با استفاده از هسته انتشار بهروز شده انجام میدهد.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
class SimpleDiffusion: def __init__( self, num_diffusion_timesteps=1000, img_shape=(3, 64, 64), device="cpu", ): self.num_diffusion_timesteps = num_diffusion_timesteps self.img_shape = img_shape self.device = device self.initialize() def initialize(self): # BETAs & ALPHAs required at different places in the Algorithm. self.beta = self.get_betas() self.alpha = 1 - self.beta self_sqrt_beta = torch.sqrt(self.beta) self.alpha_cumulative = torch.cumprod(self.alpha, dim=0) self.sqrt_alpha_cumulative = torch.sqrt(self.alpha_cumulative) self.one_by_sqrt_alpha = 1. / torch.sqrt(self.alpha) self.sqrt_one_minus_alpha_cumulative = torch.sqrt(1 - self.alpha_cumulative) def get_betas(self): """linear schedule, proposed in original ddpm paper""" scale = 1000 / self.num_diffusion_timesteps beta_start = scale * 1e-4 beta_end = scale * 0.02 return torch.linspace( beta_start, beta_end, self.num_diffusion_timesteps, dtype=torch.float32, device=self.device, ) |
کد پایتون برای فرآیند انتشار به جلو
در این بخش، ما در حال نوشتن کد پایتون هستیم تا طبق معادله ذکر شده در اینجا، “فرآیند انتشار رو به جلو” را در یک مرحله انجام دهیم.
این forward_diffusion(...)تابع دسته ای از تصاویر و گام های زمانی مربوطه را می گیرد و با استفاده از معادله به روز شده هسته انتشار به جلو ، تصاویر ورودی را اضافه می کند/تخریب می کند .
|
1
2
3
4
5
6
7
|
def forward_diffusion(sd: SimpleDiffusion, x0: torch.Tensor, timesteps: torch.Tensor): eps = torch.randn_like(x0) # Noise mean = get(sd.sqrt_alpha_cumulative, t=timesteps) * x0 # Image scaled std_dev = get(sd.sqrt_one_minus_alpha_cumulative, t=timesteps) # Noise scaled sample = mean + std_dev * eps # scaled inputs * scaled noise return sample, eps # return ... , gt noise --> model predicts this |
تجسم فرآیند انتشار رو به جلو در تصاویر نمونه
در این بخش، فرآیند انتشار رو به جلو را روی برخی از تصاویر نمونه تجسم میکنیم تا ببینیم چگونه هنگام عبور از زنجیره مارکوف برای Tمراحل زمانی، خراب میشوند.
|
1
2
3
4
5
6
7
8
9
|
sd = SimpleDiffusion(num_diffusion_timesteps=TrainingConfig.TIMESTEPS, device="cpu")loader = iter( # converting dataloader into an iterator for now. get_dataloader( dataset_name=BaseConfig.DATASET, batch_size=6, device="cpu", )) |
انجام فرآیند رو به جلو برای برخی از مراحل زمانی خاص و همچنین ذخیره نسخه های نویزدار تصویر اصلی.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
x0s, _ = next(loader)noisy_images = []specific_timesteps = [0, 10, 50, 100, 150, 200, 250, 300, 400, 600, 800, 999]for timestep in specific_timesteps: timestep = torch.as_tensor(timestep, dtype=torch.long) xts, _ = sd.forward_diffusion(x0s, timestep) xts = inverse_transform(xts) / 255.0 xts = make_grid(xts, nrow=1, padding=1) noisy_images.append(xts) |
طراحی نمونه فساد در مراحل مختلف
|
1
2
3
4
5
6
7
8
9
10
11
|
_, ax = plt.subplots(1, len(noisy_images), figsize=(10, 5), facecolor='white')for i, (timestep, noisy_sample) in enumerate(zip(specific_timesteps, noisy_images)): ax[i].imshow(noisy_sample.squeeze(0).permute(1, 2, 0)) ax[i].set_title(f"t={timestep}", fontsize=8) ax[i].axis("off") ax[i].grid(False)plt.suptitle("Forward Diffusion Process", y=0.9)plt.axis("off")plt.show() |

الگوریتم های آموزش و نمونه برداری مورد استفاده در مدل های احتمالی انتشار نویز زدایی

کد آموزشی بر اساس الگوریتم 1:
اولین تابعی که در اینجا تعریف شده است train_one_epoch(...). این تابع برای انجام “یک دوره آموزشی” استفاده می شود، یعنی با یک بار تکرار در کل مجموعه داده، مدل را آموزش می دهد و در حلقه آموزشی نهایی ما فراخوانی می شود.
ما همچنین از آموزش Mixed-Precision برای آموزش سریعتر مدل و ذخیره حافظه GPU استفاده می کنیم. کد بسیار ساده است و تقریباً یک تبدیل یک به یک از الگوریتم است.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
# Algorithm 1: Trainingdef train_one_epoch(model, loader, sd, optimizer, scaler, loss_fn, epoch=800, base_config=BaseConfig(), training_config=TrainingConfig()): loss_record = MeanMetric() model.train() with tqdm(total=len(loader), dynamic_ncols=True) as tq: tq.set_description(f"Train :: Epoch: {epoch}/{training_config.NUM_EPOCHS}") for x0s, _ in loader: # line 1, 2 tq.update(1) ts = torch.randint(low=1, high=training_config.TIMESTEPS, size=(x0s.shape[0],), device=base_config.DEVICE) # line 3 xts, gt_noise = sd.forward_diffusion(x0s, ts) # line 4 with amp.autocast(): pred_noise = model(xts, ts) loss = loss_fn(gt_noise, pred_noise) # line 5 optimizer.zero_grad(set_to_none=True) scaler.scale(loss).backward() # scaler.unscale_(optimizer) # torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) scaler.step(optimizer) scaler.update() loss_value = loss.detach().item() loss_record.update(loss_value) tq.set_postfix_str(s=f"Loss: {loss_value:.4f}") mean_loss = loss_record.compute().item() tq.set_postfix_str(s=f"Epoch Loss: {mean_loss:.4f}") return mean_loss |
کد نمونه گیری یا استنتاج بر اساس الگوریتم 2:
تابع بعدی که ما تعریف می کنیم این است reverse_diffusion(...)که مسئول انجام استنتاج است، یعنی تولید تصاویر با استفاده از فرآیند انتشار معکوس. این تابع یک مدل آموزشدیده و کلاس انتشار را میگیرد و میتواند ویدیویی ایجاد کند که کل فرآیند انتشار را به نمایش بگذارد یا فقط تصویر تولید شده نهایی را نشان دهد.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# Algorithm 2: Sampling @torch.no_grad()def reverse_diffusion(model, sd, timesteps=1000, img_shape=(3, 64, 64), num_images=5, nrow=8, device="cpu", **kwargs): x = torch.randn((num_images, *img_shape), device=device) model.eval() if kwargs.get("generate_video", False): outs = [] for time_step in tqdm(iterable=reversed(range(1, timesteps)), total=timesteps-1, dynamic_ncols=False, desc="Sampling :: ", position=0): ts = torch.ones(num_images, dtype=torch.long, device=device) * time_step z = torch.randn_like(x) if time_step > 1 else torch.zeros_like(x) predicted_noise = model(x, ts) beta_t = get(sd.beta, ts) one_by_sqrt_alpha_t = get(sd.one_by_sqrt_alpha, ts) sqrt_one_minus_alpha_cumulative_t = get(sd.sqrt_one_minus_alpha_cumulative, ts) x = ( one_by_sqrt_alpha_t * (x - (beta_t / sqrt_one_minus_alpha_cumulative_t) * predicted_noise) + torch.sqrt(beta_t) * z ) if kwargs.get("generate_video", False): x_inv = inverse_transform(x).type(torch.uint8) grid = make_grid(x_inv, nrow=nrow, pad_value=255.0).to("cpu") ndarr = torch.permute(grid, (1, 2, 0)).numpy()[:, :, ::-1] outs.append(ndarr) if kwargs.get("generate_video", False): # Generate and save video of the entire reverse process. frames2vid(outs, kwargs['save_path']) display(Image.fromarray(outs[-1][:, :, ::-1])) # Display the image at the final timestep of the reverse process. return None else: # Display and save the image at the final timestep of the reverse process. x = inverse_transform(x).type(torch.uint8) grid = make_grid(x, nrow=nrow, pad_value=255.0).to("cpu") pil_image = TF.functional.to_pil_image(grid) pil_image.save(kwargs['save_path'], format=save_path[-3:].upper()) display(pil_image) return None |
آموزش DDPM ها از ابتدا
در قسمتهای قبل، تمام کلاسها و توابع لازم برای آموزش را تعریف کردهایم. اکنون تنها کاری که باید انجام دهیم این است که آنها را جمع آوری کنیم و روند آموزش را شروع کنیم.
قبل از شروع آموزش:
- ابتدا تمام هایپرپارامترهای مربوط به مدل را تعریف می کنیم.
- سپس
UNetمدل،AdamWبهینه ساز،MSE lossتابع و سایر کلاس های لازم را مقداردهی اولیه کنید.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
@dataclassclass ModelConfig: BASE_CH = 64 # 64, 128, 256, 256 BASE_CH_MULT = (1, 2, 4, 4) # 32, 16, 8, 8 APPLY_ATTENTION = (False, True, True, False) DROPOUT_RATE = 0.1 TIME_EMB_MULT = 4 # 128model = UNet( input_channels = TrainingConfig.IMG_SHAPE[0], output_channels = TrainingConfig.IMG_SHAPE[0], base_channels = ModelConfig.BASE_CH, base_channels_multiples = ModelConfig.BASE_CH_MULT, apply_attention = ModelConfig.APPLY_ATTENTION, dropout_rate = ModelConfig.DROPOUT_RATE, time_multiple = ModelConfig.TIME_EMB_MULT,)model.to(BaseConfig.DEVICE)optimizer = torch.optim.AdamW(model.parameters(), lr=TrainingConfig.LR) # Original → Adamdataloader = get_dataloader( dataset_name = BaseConfig.DATASET, batch_size = TrainingConfig.BATCH_SIZE, device = BaseConfig.DEVICE, pin_memory = True, num_workers = TrainingConfig.NUM_WORKERS,)loss_fn = nn.MSELoss()sd = SimpleDiffusion( num_diffusion_timesteps = TrainingConfig.TIMESTEPS, img_shape = TrainingConfig.IMG_SHAPE, device = BaseConfig.DEVICE,)scaler = amp.GradScaler() # For mixed-precision training. |
سپس دایرکتوری های ورود و چک پوینت را مقداردهی اولیه می کنیم تا نتایج نمونه گیری میانی و پارامترهای مدل ذخیره شود.
|
1
2
3
4
|
total_epochs = TrainingConfig.NUM_EPOCHS + 1log_dir, checkpoint_dir = setup_log_directory(config=BaseConfig())generate_video = Falseext = ".mp4" if generate_gif else ".png" |
در نهایت می توانیم حلقه آموزشی خود را بنویسیم. همانطور که همه کدهای خود را به توابع و کلاسهای ساده و با اشکالزدایی آسان تقسیم کردهایم، اکنون تنها کاری که باید انجام دهیم این است که آنها را در epochs training loop. به طور خاص، باید توابع «آموزش» و «نمونهگیری» تعریف شده در بخش قبل را در یک حلقه فراخوانی کنیم.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
for epoch in range(1, total_epochs): torch.cuda.empty_cache() gc.collect() # Algorithm 1: Training train_one_epoch(model, sd, dataloader, optimizer, scaler, loss_fn, epoch=epoch) if epoch % 20 == 0: save_path = os.path.join(log_dir, f"{epoch}{ext}") # Algorithm 2: Sampling reverse_diffusion(model, sd, timesteps=TrainingConfig.TIMESTEPS, num_images=32, generate_video=generate_video, save_path=save_path, img_shape=TrainingConfig.IMG_SHAPE, device=BaseConfig.DEVICE, nrow=4, ) # clear_output() checkpoint_dict = { "opt": optimizer.state_dict(), "scaler": scaler.state_dict(), "model": model.state_dict() } torch.save(checkpoint_dict, os.path.join(checkpoint_dir, "ckpt.pt")) del checkpoint_dict |
اگر همه چیز به خوبی پیش برود، روند آموزشی باید شروع شود و گزارش های آموزشی مانند موارد زیر چاپ شود:

تولید تصاویر با استفاده از DDPM
اگر از نمونه های تولید شده در هر 20 دوره راضی هستید، می توانید اجازه دهید آموزش برای 800 دوره کامل شود یا در بین آن ها وقفه ایجاد کنید.
برای انجام استنتاج ، ما به سادگی باید مدل ذخیره شده را مجدداً بارگذاری کنیم، و شما می توانید از همان یا یک دایرکتوری گزارش گیری متفاوت برای ذخیره نتایج استفاده کنید. می توانید SimpleDiffusionکلاس را مجدداً راه اندازی کنید، اما لازم نیست.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# Reloading model from saved checkpointmodel = UNet( input_channels = TrainingConfig.IMG_SHAPE[0], output_channels = TrainingConfig.IMG_SHAPE[0], base_channels = ModelConfig.BASE_CH, base_channels_multiples = ModelConfig.BASE_CH_MULT, apply_attention = ModelConfig.APPLY_ATTENTION, dropout_rate = ModelConfig.DROPOUT_RATE, time_multiple = ModelConfig.TIME_EMB_MULT,)model.load_state_dict(torch.load(os.path.join(checkpoint_dir, "ckpt.tar"), map_location='cpu')['model'])model.to(BaseConfig.DEVICE)sd = SimpleDiffusion( num_diffusion_timesteps = TrainingConfig.TIMESTEPS, img_shape = TrainingConfig.IMG_SHAPE, device = BaseConfig.DEVICE,)log_dir = "inference_results" |
کد استنتاج به سادگی فراخوانی تابع reverse_diffusion(...)با استفاده از مدل آموزش دیده است.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
generate_video = False # Set it to True for generating video of the entire reverse diffusion proces or False to for saving only the final generated image.ext = ".mp4" if generate_video else ".png"filename = f"{datetime.now().strftime('%Y%m%d-%H%M%S')}{ext}"save_path = os.path.join(log_dir, filename)reverse_diffusion( model, sd, num_images=256, generate_video=generate_video, save_path=save_path, timesteps=1000, img_shape=TrainingConfig.IMG_SHAPE, device=BaseConfig.DEVICE, nrow=32,)print(save_path) |
برخی از نتایجی که به دست آوردیم:


خلاصه
در نتیجه، مدلهای انتشار نشاندهنده یک زمینه به سرعت در حال رشد با تعداد زیادی از امکانات هیجانانگیز برای آینده است. همانطور که تحقیقات در این زمینه به تکامل خود ادامه میدهد، میتوان انتظار داشت که تکنیکها و کاربردهای پیشرفتهتری نیز ظاهر شوند. من خوانندگان را تشویق می کنم تا افکار و سؤالات خود را در مورد این موضوع به اشتراک بگذارند و در گفتگو در مورد آینده مدل های انتشار شرکت کنند.
برای خلاصه کردن این مقاله📜، فهرست جامعی از موضوعات مرتبط را پوشش دادیم.
- ما با ارائه یک پاسخ شهودی به این سوال اساسی که چرا به مدلهای مولد نیاز داریم، شروع کردیم.
- سپس بحث را ادامه دادیم تا مدل های مولد مبتنی بر انتشار را از منظر منطقی و نظری توضیح دهیم.
- پس از ساختن پایه نظری، ما تمام معادلات ریاضی لازم را که برای DDPM ها به دست میآیند، یک به یک معرفی کردیم و در عین حال جریان را نیز حفظ کردیم تا درک آن آسان باشد.
- در نهایت، ما با توضیح تمام قطعات مختلف کد مورد نیاز برای آموزش DDPM ها از ابتدا و انجام استنتاج به این نتیجه رسیدیم. ما همچنین نتایجی را که از آزمایشات خود به دست آوردیم نشان دادیم.