شبکه عصبی کانولوشنال (CNN یا convnet) چیست؟
شبکه عصبی کانولوشنال (CNN یا convnet) زیر مجموعه ای از یادگیری ماشینی است. یکی از انواع مختلف شبکه های عصبی مصنوعی است که برای کاربردها و انواع داده های مختلف استفاده می شود. CNN نوعی معماری شبکه برای الگوریتم های یادگیری عمیق است و به طور خاص برای تشخیص تصویر و کارهایی که شامل پردازش داده های پیکسلی است استفاده می شود.
انواع دیگری از شبکه های عصبی در یادگیری عمیق وجود دارد، اما برای شناسایی و تشخیص اشیا، CNN ها معماری شبکه انتخابی هستند. این باعث میشود که برای کارهای بینایی کامپیوتری (CV) و برای برنامههایی که تشخیص اشیا حیاتی است، مانند ماشینهای خودران و تشخیص چهره، بسیار مناسب باشند.
در داخل شبکه های عصبی کانولوشنال
شبکههای عصبی مصنوعی (ANN) عنصر اصلی الگوریتمهای یادگیری عمیق هستند. یکی از انواع ANN یک شبکه عصبی بازگشتی (RNN) است که از داده های سری زمانی یا ترتیبی به عنوان ورودی استفاده می کند. این برای برنامه های کاربردی شامل پردازش زبان طبیعی (NLP)، ترجمه زبان، تشخیص گفتار و زیرنویس تصویر مناسب است.
CNN نوع دیگری از شبکه های عصبی است که می تواند اطلاعات کلیدی را هم در سری های زمانی و هم در داده های تصویری کشف کند. به همین دلیل، برای کارهای مرتبط با تصویر مانند تشخیص تصویر، طبقه بندی اشیا و تشخیص الگو بسیار ارزشمند است. برای شناسایی الگوهای درون یک تصویر، یک CNN از اصول جبر خطی مانند ضرب ماتریس استفاده می کند. CNN ها همچنین می توانند داده های صوتی و سیگنال را طبقه بندی کنند.
معماری CNN مشابه الگوی اتصال مغز انسان است. درست مانند مغز که از میلیاردها نورون تشکیل شده است، CNN ها نیز دارای نورون هایی هستند که به روش خاصی مرتب شده اند. در واقع، نورونهای CNN مانند لوب پیشانی مغز، ناحیهای که مسئول پردازش محرکهای بینایی است، مرتب شدهاند. این آرایش تضمین می کند که کل میدان بصری پوشانده شده است، بنابراین از مشکل پردازش تصویر تکه تکه شبکه های عصبی سنتی، که باید تصاویر را در قطعات با وضوح کاهش یافته تغذیه کنند، جلوگیری می کند. در مقایسه با شبکههای قدیمیتر، یک CNN عملکرد بهتری را با ورودیهای تصویر، و همچنین با ورودیهای سیگنال صوتی یا گفتاری ارائه میدهد.
شبکه عصبی کانولوشن، زیر مجموعه ای از یادگیری ماشین، نوعی شبکه عصبی مصنوعی است.
لایه های CNN
یک CNN یادگیری عمیق از سه لایه تشکیل شده است: یک لایه کانولوشن، یک لایه ترکیبی و یک لایه کاملاً متصل (FC). لایه کانولوشن اولین لایه است در حالی که لایه FC آخرین لایه است.
از لایه کانولوشن تا لایه FC، پیچیدگی CNN افزایش می یابد. این پیچیدگی فزاینده است که به CNN اجازه می دهد تا به طور متوالی بخش های بزرگتر و ویژگی های پیچیده تر یک تصویر را شناسایی کند تا در نهایت شیء را به طور کامل شناسایی کند.
لایه کانولوشن. اکثر محاسبات در لایه کانولوشن، که بلوک اصلی یک CNN است، انجام می شود. یک لایه کانولوشنال دوم می تواند از لایه کانولوشن اولیه پیروی کند. فرآیند کانولوشن شامل یک هسته یا فیلتر در داخل این لایه است که در فیلدهای پذیرنده تصویر حرکت می کند و بررسی می کند که آیا ویژگی در تصویر وجود دارد یا خیر.
با تکرارهای متعدد، هسته کل تصویر را جارو می کند. پس از هر بار تکرار، یک محصول نقطه ای بین پیکسل های ورودی و فیلتر محاسبه می شود. خروجی نهایی از سری نقاط به عنوان نقشه ویژگی یا ویژگی پیچیده شناخته می شود. در نهایت، تصویر در این لایه به مقادیر عددی تبدیل میشود که به CNN اجازه میدهد تصویر را تفسیر کرده و الگوهای مربوطه را از آن استخراج کند.
لایه ادغام. مانند لایه کانولوشن، لایه ادغام نیز یک هسته یا فیلتر را در سراسر تصویر ورودی جارو می کند. اما برخلاف لایه کانولوشن، لایه ادغام تعداد پارامترهای ورودی را کاهش می دهد و همچنین منجر به از دست دادن اطلاعات می شود. از جنبه مثبت، این لایه پیچیدگی را کاهش می دهد و کارایی CNN را بهبود می بخشد.
لایه کاملا متصل لایه FC جایی است که طبقه بندی تصاویر در CNN بر اساس ویژگی های استخراج شده در لایه های قبلی انجام می شود. در اینجا کاملا متصل به این معنی است که تمام ورودی ها یا گره های یک لایه به هر واحد فعال سازی یا گره لایه بعدی متصل می شوند.
تمام لایه های CNN به طور کامل به هم متصل نیستند زیرا منجر به ایجاد یک شبکه متراکم غیر ضروری می شود. همچنین تلفات را افزایش می دهد و بر کیفیت خروجی تأثیر می گذارد و از نظر محاسباتی گران تمام می شود.
شبکه های عصبی کانولوشن چگونه کار می کنند؟
یک CNN میتواند چندین لایه داشته باشد، که هر یک از آنها میآموزد ویژگیهای مختلف یک تصویر ورودی را تشخیص دهد. یک فیلتر یا کرنل روی هر تصویر اعمال میشود تا خروجیای تولید کند که پس از هر لایه به تدریج بهتر و با جزئیات بیشتر میشود. در لایه های پایین، فیلترها می توانند به عنوان ویژگی های ساده شروع شوند.
در هر لایه متوالی، فیلترها برای بررسی و شناسایی ویژگی هایی که به طور منحصر به فرد شی ورودی را نشان می دهند، پیچیدگی بیشتری پیدا می کنند. بنابراین، خروجی هر تصویر پیچیده – تصویری که بعد از هر لایه تا حدی شناسایی می شود – به ورودی لایه بعدی تبدیل می شود. در آخرین لایه که یک لایه FC است، CNN تصویر یا شیئی را که نشان می دهد تشخیص می دهد.
با کانولوشن، تصویر ورودی از مجموعه ای از این فیلترها عبور می کند. همانطور که هر فیلتر ویژگی های خاصی را از تصویر فعال می کند، کار خود را انجام می دهد و خروجی خود را به فیلتر لایه بعدی منتقل می کند. هر لایه یاد می گیرد که ویژگی های مختلف را شناسایی کند و در نهایت عملیات برای ده ها، صدها یا حتی هزاران لایه تکرار می شود. در نهایت، تمام دادههای تصویری که از طریق لایههای چندگانه CNN در حال پیشرفت هستند به CNN اجازه میدهند تا کل شی را شناسایی کند.

جدولی که تفاوت بین شبکه عصبی کانولوشن در مقابل شبکه عصبی تکراری را نشان می دهد.
CNN ها در مقابل شبکه های عصبی
بزرگترین مشکل شبکه های عصبی معمولی (NN) عدم مقیاس پذیری است. برای تصاویر کوچکتر با کانال های رنگی کمتر، یک NN معمولی ممکن است نتایج رضایت بخشی ایجاد کند. اما با افزایش اندازه و پیچیدگی یک تصویر، نیاز به قدرت و منابع محاسباتی نیز افزایش مییابد که نیاز به یک NN بزرگتر و گرانتر دارد.
علاوه بر این، مشکل بیش از حد برازش نیز در طول زمان به وجود می آید، که در آن NN سعی می کند جزئیات زیادی را در داده های آموزشی یاد بگیرد. همچنین ممکن است نویز موجود در داده ها را یاد بگیرد که بر عملکرد آن در مجموعه داده های آزمایشی تأثیر می گذارد. در نهایت، NN نمی تواند ویژگی ها یا الگوهای موجود در مجموعه داده و در نتیجه خود شی را شناسایی کند.
در مقابل، یک CNN از اشتراک گذاری پارامترها استفاده می کند. در هر لایه از CNN، هر گره به دیگری متصل می شود. یک CNN همچنین دارای وزن مرتبط است. همانطور که فیلترهای لایه ها در سراسر تصویر حرکت می کنند، وزن ها ثابت می مانند – شرایطی که به عنوان اشتراک پارامتر شناخته می شود. این باعث می شود که کل سیستم CNN از نظر محاسباتی کمتر از یک سیستم NN فشرده شود.
مزایای استفاده از CNN برای یادگیری عمیق
یادگیری عمیق زیرمجموعه ای از یادگیری ماشینی است که از شبکه های عصبی با حداقل سه لایه استفاده می کند. در مقایسه با یک شبکه تنها با یک لایه، یک شبکه با چندین لایه می تواند نتایج دقیق تری ارائه دهد. هر دو RNN و CNN بسته به کاربرد در یادگیری عمیق استفاده می شوند.
برای تشخیص تصویر، طبقهبندی تصویر و برنامههای بینایی کامپیوتری (CV)، CNNها بهویژه مفید هستند زیرا نتایج بسیار دقیقی را ارائه میدهند، بهویژه زمانی که دادههای زیادی درگیر باشد. سیانان همچنین ویژگیهای شی را در تکرارهای متوالی با حرکت دادههای شی در میان لایههای متعدد CNN، یاد میگیرد. این یادگیری مستقیم (و عمیق) نیاز به استخراج دستی ویژگی (مهندسی ویژگی) را از بین می برد.
سیانانها را میتوان برای وظایف شناسایی جدید بازآموزی کرد و بر روی شبکههای از قبل موجود ساخت. این مزایا فرصتهای جدیدی را برای استفاده از CNN برای برنامههای کاربردی دنیای واقعی بدون افزایش پیچیدگیهای محاسباتی یا هزینهها باز میکند.
همانطور که قبلا دیده شد، CNN ها از نظر محاسباتی کارآمدتر از NN های معمولی هستند زیرا از اشتراک پارامترها استفاده می کنند. این مدل ها به راحتی قابل استقرار هستند و می توانند روی هر دستگاهی از جمله گوشی های هوشمند اجرا شوند.
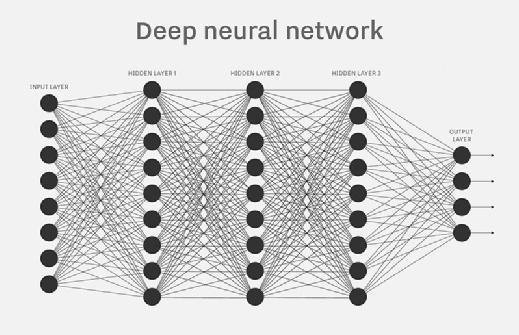
نمودار نشان می دهد که چگونه یک شبکه عصبی داده ها را پردازش می کند.
کاربردهای شبکه های عصبی کانولوشنال
شبکههای عصبی کانولوشنال در حال حاضر در انواع کاربردهای CV و تشخیص تصویر استفاده میشوند. برخلاف برنامههای کاربردی ساده تشخیص تصویر، CV سیستمهای محاسباتی را قادر میسازد تا اطلاعات معنیداری را از ورودیهای بصری (مثلاً تصاویر دیجیتال) استخراج کنند و سپس بر اساس این اطلاعات اقدامات مناسب را انجام دهند.
رایج ترین کاربردهای CV و CNN در زمینه هایی مانند موارد زیر استفاده می شود:
- مراقبت های بهداشتی. CNN ها می توانند هزاران گزارش تصویری را برای تشخیص هر گونه شرایط غیرعادی در بیماران، مانند وجود سلول های سرطانی بدخیم، بررسی کنند.
- خودرو. فناوری CNN به تحقیقات در مورد وسایل نقلیه خودران و خودروهای خودران کمک می کند.
- رسانه های اجتماعی. پلتفرمهای رسانههای اجتماعی از CNN برای شناسایی افراد در عکس کاربر و کمک به کاربر برای تگ کردن دوستان خود استفاده میکنند.
- خرده فروشی. پلتفرمهای تجارت الکترونیکی که جستجوی بصری را در بر میگیرند به برندها اجازه میدهند اقلامی را پیشنهاد کنند که احتمالاً برای خریدار جذاب هستند.
- تشخیص چهره برای مجریان قانون شبکههای متخاصم مولد (GAN) برای تولید تصاویر جدید استفاده میشوند که سپس میتوانند برای آموزش مدلهای یادگیری عمیق برای تشخیص چهره استفاده شوند.
- پردازش صدا برای دستیاران مجازی CNN ها در دستیارهای مجازی کلمات کلیدی گفته شده توسط کاربر را یاد می گیرند و تشخیص می دهند و ورودی را پردازش می کنند تا اقدامات آنها را هدایت کند و به کاربر پاسخ دهد.
نحوه ساخت یک مدل یادگیری ماشینی را در 7 مرحله بیاموزید و ببینید چگونه یادگیری ماشین خودکار کارایی پروژه را بهبود می بخشد.