شبکه های عصبی مکرر چیست؟
شبکه عصبی بازگشتی نوعی شبکه عصبی مصنوعی است که معمولاً در تشخیص گفتار و پردازش زبان طبیعی استفاده میشود. شبکه های عصبی مکرر ویژگی های متوالی داده ها را تشخیص می دهند و از الگوها برای پیش بینی سناریوی احتمالی بعدی استفاده می کنند.
RNN ها در یادگیری عمیق و در توسعه مدل هایی استفاده می شوند که فعالیت نورون ها را در مغز انسان شبیه سازی می کنند. آنها به ویژه در موارد استفاده که زمینه برای پیشبینی یک نتیجه حیاتی است، قدرتمند هستند و همچنین از دیگر انواع شبکههای عصبی مصنوعی متمایز هستند زیرا از حلقههای بازخورد برای پردازش دنبالهای از دادهها استفاده میکنند که خروجی نهایی را اعلام میکند. این حلقههای بازخورد اجازه میدهند تا اطلاعات باقی بماند. این اثر اغلب به عنوان حافظه توصیف می شود.
موارد استفاده از RNN به مدلهای زبانی متصل میشوند که در آن دانستن حرف بعدی در یک کلمه یا کلمه بعدی در یک جمله بر اساس دادههای قبل از آن است. یک آزمایش متقاعد کننده شامل یک RNN است که با آثار شکسپیر آموزش دیده تا نثری شبیه شکسپیر را با موفقیت تولید کند. نوشتن توسط RNN ها نوعی خلاقیت محاسباتی است. این شبیهسازی خلاقیت انسان با درک گرامر و معناشناسی هوش مصنوعی که از مجموعه آموزشی آن به دست میآید امکانپذیر شده است.
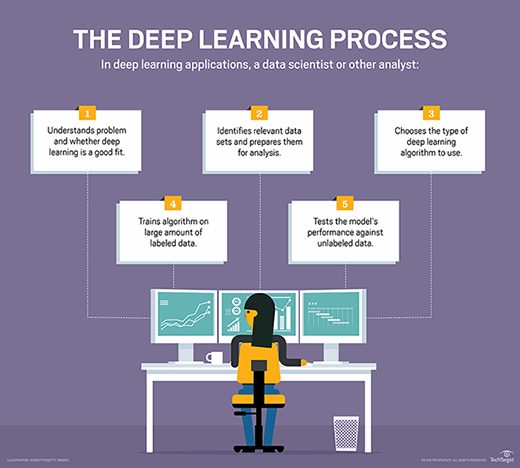
فرآیند یادگیری عمیق نشان داده شده است.
نحوه یادگیری شبکه های عصبی مکرر
شبکههای عصبی مصنوعی با اجزای پردازش دادههای به هم پیوسته ایجاد میشوند که به طور ضعیفی برای عملکرد مانند مغز انسان طراحی شدهاند. آنها از لایههایی از نورونهای مصنوعی – گرههای شبکه – تشکیل شدهاند که توانایی پردازش ورودی و ارسال خروجی به سایر گرههای شبکه را دارند. گره ها توسط لبه ها یا وزنه هایی به هم متصل می شوند که بر قدرت سیگنال و خروجی نهایی شبکه تأثیر می گذارد.
در برخی موارد، شبکه های عصبی مصنوعی اطلاعات را در یک جهت از ورودی تا خروجی پردازش می کنند. این شبکههای عصبی «پیشخور» شامل شبکههای عصبی کانولوشنی هستند که زیربنای سیستمهای تشخیص تصویر هستند. از سوی دیگر، RNN ها می توانند برای پردازش اطلاعات در دو جهت لایه بندی شوند.
مانند شبکه های عصبی پیشخور، RNN ها می توانند داده ها را از ورودی اولیه تا خروجی نهایی پردازش کنند. برخلاف شبکههای عصبی پیشخور، RNNها از حلقههای بازخورد، مانند انتشار پسانداز در طول زمان، در طول فرآیند محاسباتی برای بازگرداندن اطلاعات به شبکه استفاده میکنند. این ورودی ها را به هم متصل می کند و همان چیزی است که RNN ها را قادر می سازد تا داده های متوالی و زمانی را پردازش کنند.
یک پس انتشار کوتاه شده در طول شبکه عصبی زمان یک RNN است که در آن تعداد مراحل زمانی در دنباله ورودی با برش دنباله ورودی محدود می شود. این برای شبکه های عصبی مکرر که به عنوان مدل های دنباله به دنباله استفاده می شوند مفید است، جایی که تعداد مراحل در دنباله ورودی (یا تعداد مراحل زمانی در دنباله ورودی) بیشتر از تعداد مراحل در دنباله خروجی است. .
شبکه های عصبی بازگشتی دو طرفه
شبکه های عصبی بازگشتی دو طرفه (BRNN) نوع دیگری از RNN هستند که به طور همزمان جهت های رو به جلو و عقب جریان اطلاعات را یاد می گیرند. این با RNN های استاندارد که فقط اطلاعات را در یک جهت یاد می گیرند متفاوت است. فرآیند یادگیری هر دو جهت به طور همزمان به عنوان جریان اطلاعات دو طرفه شناخته می شود.
در یک شبکه عصبی مصنوعی معمولی، پیش بینی های رو به جلو برای پیش بینی آینده و پیش بینی های عقب برای ارزیابی گذشته استفاده می شود. با این حال، آنها مانند یک BRNN با هم استفاده نمی شوند.
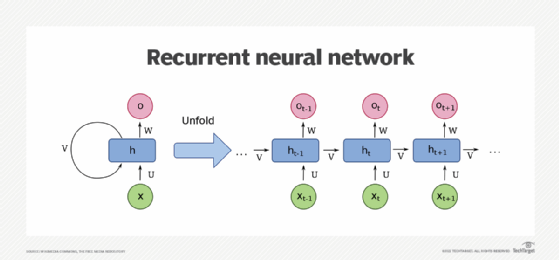
نموداری — توسط Wikimedia Commons — که یک RNN یک واحدی را نشان می دهد. پایین حالت ورودی است. میانه، حالت پنهان؛ بالا، حالت خروجی U، V، W وزن های شبکه هستند. نسخه فشرده شده نمودار در سمت چپ، نسخه باز کردن در سمت راست.
چالش های RNN و نحوه حل آنها
رایج ترین مشکلات با RNNS مشکلات ناپدید شدن گرادیان و انفجار است. گرادیان به خطاهای ایجاد شده به عنوان قطار شبکه عصبی اشاره دارد. اگر شیب ها شروع به انفجار کنند، شبکه عصبی ناپایدار می شود و قادر به یادگیری از داده های آموزشی نیست.
واحدهای حافظه کوتاه مدت بلند مدت
یکی از اشکالات RNN های استاندارد، مشکل گرادیان ناپدید شدن است، که در آن عملکرد شبکه عصبی آسیب می بیند زیرا نمی توان آن را به درستی آموزش داد. این اتفاق با شبکههای عصبی لایهای عمیق میافتد که برای پردازش دادههای پیچیده استفاده میشوند.
RNN های استانداردی که از روش یادگیری مبتنی بر گرادیان استفاده می کنند، با بزرگتر شدن و پیچیده تر شدن، تخریب می شوند. تنظیم موثر پارامترها در لایه های اولیه بسیار وقت گیر و از نظر محاسباتی گران می شود.
یکی از راه حل های این مشکل، شبکه های حافظه کوتاه مدت بلند مدت (LSTM) نامیده می شود که دانشمندان علوم کامپیوتر Sepp Hochreiter و Jurgen Schmidhuber در سال 1997 اختراع کردند. RNN های ساخته شده با واحدهای LSTM داده ها را به سلول های حافظه کوتاه مدت و بلند مدت دسته بندی می کنند. انجام این کار به RNN ها امکان می دهد بفهمند کدام داده مهم است و باید به خاطر بسپارد و دوباره به شبکه بازگرداند. همچنین RNN ها را قادر می سازد تا بفهمند چه داده هایی را می توان فراموش کرد.
واحدهای مکرر دردار
واحدهای بازگشتی دروازهای (GRUs) شکلی از واحد شبکه عصبی بازگشتی هستند که میتوانند برای مدلسازی دادههای متوالی استفاده شوند. در حالی که شبکههای LSTM را میتوان برای مدلسازی دادههای متوالی نیز استفاده کرد، آنها نسبت به شبکههای پیشخور استاندارد ضعیفتر هستند. با استفاده از یک LSTM و یک GRU با هم، شبکه ها می توانند از نقاط قوت هر دو واحد بهره ببرند – توانایی یادگیری ارتباطات بلندمدت برای LSTM و توانایی یادگیری از الگوهای کوتاه مدت برای GRU.
پرسپترون های چندلایه و شبکه های عصبی کانولوشنال
دو نوع دیگر از کلاسهای شبکههای عصبی مصنوعی شامل پرسپترونهای چندلایه (MLPs) و شبکههای عصبی کانولوشنال هستند.
MLP ها از چندین نورون تشکیل شده اند که در لایه ها مرتب شده اند و اغلب برای طبقه بندی و رگرسیون استفاده می شوند. پرسپترون الگوریتمی است که می تواند انجام یک کار طبقه بندی دودویی را یاد بگیرد. یک پرسپترون منفرد نمی تواند ساختار خود را تغییر دهد، بنابراین آنها اغلب در لایه هایی در کنار هم قرار می گیرند، جایی که یک لایه یاد می گیرد ویژگی های کوچکتر و خاص مجموعه داده را تشخیص دهد.
نورون ها در لایه های مختلف به یکدیگر متصل هستند. به عنوان مثال، خروجی نورون اول به ورودی نورون دوم متصل می شود که به عنوان یک فیلتر عمل می کند. MLP ها برای نظارت بر یادگیری و برای کاربردهایی مانند تشخیص نوری کاراکتر، تشخیص گفتار و ترجمه ماشینی استفاده می شوند.
شبکههای عصبی کانولوشنال که با نام CNN نیز شناخته میشوند، خانوادهای از شبکههای عصبی هستند که در بینایی کامپیوتری استفاده میشوند. اصطلاح “convolutional” به پیچیدگی – فرآیند ترکیب نتیجه یک تابع با فرآیند محاسبه / محاسبه آن – تصویر ورودی با فیلترهای شبکه اشاره دارد. ایده این است که ویژگی ها یا ویژگی ها را از تصویر استخراج کنید. سپس می توان از این ویژگی ها برای برنامه هایی مانند تشخیص یا تشخیص اشیا استفاده کرد.

تفاوت های اصلی بین یک شبکه عصبی بازگشتی و یک شبکه عصبی کانولوشن
CNN ها از طریق یک فرآیند آموزش ایجاد می شوند، که تفاوت اصلی بین CNN و سایر انواع شبکه های عصبی است. CNN از چندین لایه نورون تشکیل شده است و هر لایه نورون مسئول یک وظیفه خاص است. اولین لایه نورونها ممکن است مسئول شناسایی ویژگیهای کلی یک تصویر، مانند محتویات آن (به عنوان مثال، یک سگ) باشد. لایه بعدی نورون ها ممکن است ویژگی های خاص تری را شناسایی کند (مثلاً نژاد سگ).