بیان مسأله
مجموعه داده ای از تصاویر راننده که توسط دوربین نصب شده در داخل خودرو گرفته شده است به ما داده می شود. هدف ما پیشبینی احتمال کاری است که راننده در هر تصویر انجام میدهد. 10 دسته وجود دارد – رانندگی ایمن، پیامک – راست، صحبت کردن با تلفن – راست، پیامک – چپ، صحبت کردن با تلفن – چپ، کار با رادیو، نوشیدن، دست زدن به پشت، مو و آرایش، صحبت با مسافر. 22424 نمونه آموزشی و 79726 نمونه آزمایشی به ما داده شده است. برای هر تصویر آزمایشی، مدل ما باید یک مقدار احتمال را به هر یک از 10 حالت رانندگی اختصاص دهد.
در زیر نمونه هایی از تصاویر آموزشی با برچسب های مربوطه را مشاهده می کنید:

این متریک از دست دادن آنتروپی متقاطع چند کلاسه است (از دست دادن لگاریتمی نیز نامیده می شود).
رویکرد ما
ما یک خط لوله یادگیری عمیق معمولی را راهاندازی کردیم که شامل پیشپردازش دادهها، تقویت دادهها، تنظیم دقیق مدلهای مختلف شبکههای از پیش آموزشدیده شده، و در نهایت مجموعه آن مدلها برای به دست آوردن پیشبینی نهایی برای ارسال است.

پیش پردازش داده ها تصاویر را از 640×480 به 224×224 کاهش می دهیم تا ابعاد با ابعاد مورد نیاز Convnet های از پیش آموزش دیده ای که برای تنظیم دقیق استفاده می کنیم سازگار باشد. تصاویر ورودی نمونه پایین یک روش معمول برای اطمینان از اینکه مدل و نمونههای آموزشی مربوطه (از یک مینی دسته) میتوانند در حافظه کارت گرافیک قرار گیرند، است.
افزایش داده ها با انجام چرخشها و ترجمههای تصادفی روی هر نمونه تصویر، اندازه مجموعه داده اصلی را دو برابر میکنیم. آموزش بر روی مجموعه داده افزوده شده، مدل حاصل را قویتر و کمتر مستعد اضافه کردن میکند.
تنظیم دقیق شبکه های از پیش آموزش دیده این مسابقه به شرکتکنندگان اجازه میدهد از شبکههای از پیش آموزشدیدهشده در مجموعه دادههای خارجی استفاده کنند. از این رو، به جای آموزش یک Covnet از ابتدا، که به دلیل اندازه کوچک مجموعه داده، نتیجه خوبی به ما نمی داد، از Covnet های از پیش آموزش دیده شده در ImageNet ( تصاویر دارای برچسب 1.2 میلیون) استفاده می کنیم.
ما چندین مدل Convnet، یعنی VGG16 ، VGG19 ، و GoogleNet (Inception) را در هر دو مجموعه داده اصلی و افزوده تنظیم دقیق می کنیم . برای هر مدل، لایه بالایی (لایه softmax با 1000 دسته برای ImageNet) را با لایه softmax جدید خود با 10 دسته که هر کدام یک حالت رانندگی را نشان میدهند، کوتاه کرده و جایگزین میکنیم.
ما از اعتبار سنجی متقاطع 5 برابری (cv) استفاده می کنیم و شیب نزولی تصادفی را با انتشار برگشتی اجرا می کنیم. خروجی تک مدل ما میانگین هندسی 5 بردار پیش بینی cv است.
یادگیری نیمه نظارتی ایده یادگیری نیمه نظارتی این است که یک مدل پایه را آموزش دهیم، از مدل پایه برای به دست آوردن پیشبینیها در مجموعه آزمایشی استفاده کنیم، سپس از آن پیشبینیها به عنوان برچسب استفاده کنیم و دوباره روی قطار و مجموعه آزمایشی آموزش دهیم. در مورد ما، ما یادگیری نیمه نظارتی را در VGG16 انجام می دهیم. این منجر به بهبود متوسطی در امتیاز تابلوی امتیازات می شود.
آزمایش افزایش داده ها در طول زمان تست، هر تصویر آزمایشی را با چرخش و ترجمه تصادفی تقویت میکنیم و میانگین پیشبینی هر نسخه تبدیلشده از تصویر آزمایشی را برای به دست آوردن پیشبینی نهایی روی آن تصویر بهدست میآوریم. این باعث بهبود بیشتر امتیاز تابلوی امتیازات ما می شود.
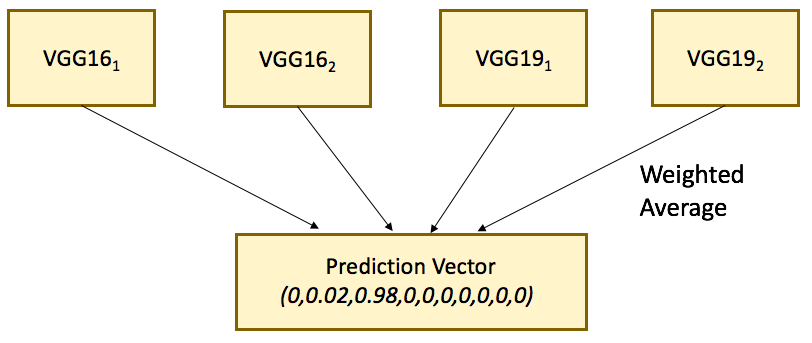
گروه مدل. همانند سایر رقابتهای Kaggle یا تجزیه و تحلیل پیشبینیکننده، ارسال نهایی معمولاً ترکیبی از 2 یا چند مدل پایه مختلف است. ما مدل های مختلف را با میانگین حسابی وزنی ترکیب می کنیم. پیش بینی نهایی ما میانگین وزنی 4 مدل VGG است. ما مدل Inception GoogLeNet را در این ترکیب لحاظ نکردیم زیرا امتیاز رتبهبندی عمومی بدتری را برای ما به ارمغان آورد.
نتیجه نهایی
در پایان مسابقات، تیم ما به رتبه نهایی 17 از 1450 (2٪ برتر) در جدول امتیازات عمومی و 47 از 1450 (4٪ برتر) در جدول امتیازات خصوصی دست یافت که به اندازه کافی خوب است که ما را به یک امتیاز برساند. مدال نقره . با این حال، ما یک لغزش بزرگ از تابلوی امتیازات عمومی به تابلوی امتیازات خصوصی را تجربه کردیم. بدیهی است که پیشبینیهای خود را بیش از حد به تابلوی امتیازات عمومی تطبیق دادیم.
![]()
درس های آموخته شده
یکی از چیزهای مهم در مورد Kaggle، قدرت جامعه است. برای هر مسابقه، یک انجمن مجزا وجود دارد که در آن تیمهای شرکتکننده اسکریپتها را به اشتراک میگذارند و ایدههای خود را از یکدیگر باز میگردانند. انجمن معمولاً بسیار فعال است و اکثر شرکت کنندگان مایلند بینش خود را بدون خودخواهی به اشتراک بگذارند.
پس از پایان مسابقه، بسیاری از تیم های برتر راه حل های خود را در انجمن به اشتراک گذاشتند. در زیر ایده های جالبی وجود دارد که از مطالعه رویکردهای تیم های دیگر آموخته ایم.
1. استفاده از سایر مدل های پیشرفته.
اکثر تیم های برتر از ResNet و Inception در گروه نهایی خود استفاده می کنند. ResNet و Inception مدل های اخیرا منتشر شده و احتمالاً پیشرفته تری هستند که در بسیاری از معیارهای عملکرد از VGG پیشی می گیرند.
به ویژه، ResNet پیشرفته ترین و برنده چالش ImageNet 2015 است. تقریباً همه تیم های برتر ResNet را در راه حل های خود گنجانده اند. برخی از تیم ها فقط از ResNet استفاده می کنند و توانستند به نتایج بسیار خوبی دست پیدا کنند.
ما از ResNet استفاده نکردیم زیرا نسخه از پیش آموزش داده شده ImageNet در Keras در آن زمان در دسترس نبود ( اکنون در اینجا موجود است !). اگرچه ما مدل Inception را امتحان کردیم، اما به نحوی توانست امتیاز بدتری را به ما بدهد، بنابراین آن را از گروه نهایی خود خارج کردیم. در گذشته، افزودن مدل اولیه به ترکیب ما باعث جهش بیش از 10 موقعیت در لیدربرد خصوصی می شود! تطبیق بیش از حد در جدول امتیازات عمومی مطمئناً برای ما گران تمام شد.
2. یک معیار اعتبار متقاطع محلی قابل اعتماد ایجاد کنید
یکی از بزرگترین اشتباهاتی که مرتکب شدیم، عدم ایجاد یک معیار اعتبار متقاطع محلی (cv) قابل اعتماد است. در نتیجه، ما چارهای نداشتیم جز اینکه پیشبینیهای خود را بیش از حد به تابلوی امتیازات عمومی تطبیق دهیم، که واقعاً ایده بدی بود. در نیمه راه رقابت، ما Stack Generalization را امتحان کردیم تا مدل های پایه خود را جمع کنیم. آن طور که انتظار می رفت نتیجه نگرفت و منجر به نادیده گرفتن کامل نمره رزومه محلی در بخش بعدی مسابقه شد.
در واقع، به دلیل ماهیت این مجموعه داده، ایجاد یک معیار cv محلی خوب برای این رقابت آسان نیست. تعداد زیادی تصاویر روی تعداد کمی از درایورها وجود دارد و درایورهایی که در مجموعه آموزشی ظاهر می شوند در مجموعه آزمایشی ظاهر نمی شوند.
3. پیش پردازش تصویر
هدف از این مسابقه شناسایی رفتار رانندگان در خودرو است. همانطور که گفته شد، ما باید مدل خود را بر روی بخشی از تصویر متمرکز کنیم که راننده را در بر می گیرد و قسمت بی فایده تصویر، مثلاً، قسمت عقب خودرو را که ممکن است نویز نامطلوب ایجاد کند، قطع کند. بسیاری از تیم های برتر با استفاده از روش های مختلف از جمله R-CNN و VGG-CAM دقیقاً این کار را انجام می دهند . یکی از 10 تیم برتر حتی بر روی صدها تصویر (خودش!) دستی برش می دهد و روی بقیه تصاویر رگرسیون جعبه مرزی را اجرا می کند.
4. و مهمترین ترفند از همه – K Nearest Neighbor
اگرچه مجموعه داده شامل بیش از 10000 تصویر در قطار و مجموعه آزمایشی ترکیبی است، تنها کمتر از 100 راننده به ترتیب در قطار و مجموعه آزمایش تحت پوشش قرار گرفتند. در واقع، تک تک تصاویر نمونههای مجزایی بودند که از ویدیوهای گرفته شده توسط دوربین داخل خودرو استخراج میشدند. از این رو، می توان از بعد زمانی بهره برداری کرد و توالی تصاویر را به ترتیب زمانی بازسازی کرد. به نظر می رسد که تصاویری که به این ترتیب ردیف شده اند، همبستگی زیادی با یکدیگر دارند.
چند تیم برتر موفق شدند از این واقعیت استفاده کنند و K Nearest Neighbor (KNN) را برای گروهبندی تصاویر در خوشههای بسیار همبسته و میانگین پیشبینی نزدیکترین همسایگان برای به دست آوردن پیشبینی نهایی انجام دهند. به گفته برنده مسابقه، میانگین KNN به تنهایی 40 درصد از امتیاز تابلوی رهبران عمومی را کاهش می دهد!
نتیجه گیری و اندیشه های نهایی
این اولین تلاش جدی من در Deep Learning است و از این فرصت بسیار سپاسگزارم. اگرچه لغزش نهایی در جدول امتیازات سطحی از ناامیدی را به همراه داشت، اما در مقایسه با میزان یادگیری و هیجان ذهنی که به وجود آمد، ناچیز است.
من فکر می کنم سهم رقابت Kaggle در یادگیری عمیق قطعاً در بخش مدل سازی نیست. هیچ یک از تیم ها معماری های عصبی جدیدی را به خاطر این رقابت اختراع نمی کنند. بیشتر در مورد ترفندها، هکها و تکنیکهای به کار رفته در بخشهای پیشپردازش داده و مجموعهای از مدلها است، به عنوان مثال، استنتاج VGG-CAM، برش دستی و رگرسیون جعبه محدود، روشهای جدید لرزش رنگ و غیره، که در عمل خوب کار میکنند، اما به ندرت انجام میشوند. در مورد آن صحبت شده یا توسط جامعه دانشگاهی کاملاً نادیده گرفته شده است.
اگر سوال یا نظری دارید در زیر کامنت بگذارید.
مقاله ترجمه شده از این سایت هست